Linux基础 帮助命令 man帮助命令 当你不知道Linux命令如何使用的时候,使用man命令帮助你
–help命令 1 2 Linux的命令 --help eg:ls --help
help命令获取帮助 与man命令用法类似,但是只针对bash内置命令,局限性较大。
1 2 help Linux的命令 eg:help ls
info命令获取帮助 1 2 info Linux的命令 eg:info ls
绝对/相对路径 只要不是从根目录开始寻找,就是相对路径。
eg:/home/qinhuai/data/userinfo即为绝对路径
在/home/qinhuai目录下的 ./data/userinfo即为相对路径
Linux开关机命令 shutdown重启 1 2 3 4 shoutdown -r[分钟] shoutdown -r 10 十分钟后重启 shoutdown -r 0 立即重启,等同于 shoutdown -r now
shoutdown关机 1 2 3 4 shoutdown -h[分钟] shoutdown -h 10 十分钟后关机 shoutdown -h 0 立即关机,等同于shoutdown now
reboot重启 Linux命令行常用快捷键 1 2 3 4 5 6 ctrl + c cancel取消当前操作 ctrl + l 清空屏幕内容 ctrl + d 退出当前用户 ctrl + a 光标移动到行首 ctrl + e 光标移动到行尾 ctrl + u 删除光标到行首的内容
Linux的环境变量 环境变量PATH,系统会按照PATH的设定区每个PATH定义的目录下搜索可执行文件。
1 2 3 执行命令: echo $PATH 输出PATH的变量
管道符
用法
1 2 3 1.对字符串进行二次过滤 查看test1文本中的内容,并且对输出内容进行二次过滤,过滤出关键词 cat test1 | grep "关键词"
Linux通配符 通配符即键盘上一些特殊字符,可以实现特殊的功能,例如模糊搜索一些文件。
符号
作用
*
匹配任意,0或多个字符,字符串
?
匹配任意1个字符,有且只有一个字符
符号集合 匹配一堆字符或文本
[abcd]
匹配abcd中任意一个字符,abcd也可以是不连续任意字符
[a-z]
匹配a到z之间任意一个字符,要求连续字符,也可以连续数字,匹配[1-9]
[!abcd]
不匹配括号中任意一个字符,也可以书写成[!a-d],同于写法
[^abcd]
同上,!可以改成^
特殊通配符
符号
作用
[[:upper:]]
所有大写字母
[[:lower:]]
所有小写字母
[[:alpha:]]
所有字母
[[:digit:]]
所有数字
[[:alnum:]]
所有的字母和数字
[[:space:]]
所有的空白字符
[[:punct:]]
所有标点符号
1 2 找出根目录下最大文件夹深度是3,且所有以l开头的文件,且以小写字母结尾,中间出现任意字符的文本文件 find / -maxdepth 3 -type f -name "l?[a-z]"
特殊引号 在Linux系统中,单引号、双引号可以用于表示字符串。
名称
解释
单引号’’
所见即所得,强引用,单引号中内容会原样输出
双引号””
弱引用,能够识别各种特殊符号、变量、转义符等,解析出在输出结果
没有引号
一般连续字符串、数字、路径可以省略双引号;遇见特殊字符、空格、变量等,必须加上双引号。
反引号``
常用于引用命令结果,同于$(命令)
eg:
文件描述符 在Linux系统中,一切的设备都看作是文件,而每打开一个文件,就会有一个代表打开文件的文件描述符
程序启动时默认打开三个I/O设备文件:
标准输入文件stdin,文件描述符0
标准输出文件stdout,文件描述符1
标准错误输出文件stderr,文件描述符2
符号
特殊符号
简介
标准输入stdin
代码为0,配合<或<<
数据流从右向左⬅️
标准输出stdout
代码为1,配合>或>>
数据流从左向右➡️
标准错误输出stderr
代码为2,配合>或>>
数据流从左向右➡️
重定向符号 数据流就是箭头的方向
标准输入重定向
0< 或 <
数据一般从文件流向处理命令
追加输入重定向
0<< 或 <<
数据一般从文件流向处理命令
标准输出重定向
1> 或 >
正常输出重定向给文件,默认覆盖
标准输出追加重定向
1>> 或 >>
内容追加重定向到文件底部,追加
标准错误输出重定向
2>
将标准错误内容重定向到文件,默认覆盖
标准错误输出追加重定向
2>>
将标准错误内容追加到文件底部
重定向符号 重定向:将数据传到其他地方
符号
解释
>
输出覆盖重定向
>>
输出追加重定向
<或<<
标准输入重定向
eg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1.读取文件内容,且写入到另一个文件中,覆盖写入文件内容 cat test1 > test2 2.追加写入文件内容 cat test1 >> test2 3.重定向写入 cat < test1 把文件中的数据发送给cat命令去读取 将文本内容拆分成多行 xargs -n 4 < test1 将test1文件中的内容拆分成以4为单位的内容输出 4.重定向追加写入符 cat >> 需要写入的文件 <<EOF 内容 内容 内容 EOF
特殊重定向,合并重定向 **2>&1**把标准错误,重定向到标准输出
把命令的执行结果写入到文件,标准错误当作标准输出处理,也写入文件
Command > /path/file 2&1
输入重定向 数据流输入
1 2 3 Command < 文件数据 可用于恢复数据库 mysql -uroot -p < 数据库.sql
其他特殊符号
符号
解释
;
分号,命令分隔符或是结束符
#
1.文件中注释的额内容。
|
管道符,传递命令结果给下一个命令
$
1.$变量,取出变量的值。
\
转义符,将特殊含义的字符还原成普通字符
{}
1.生成序列。
逻辑操作符
命令
解释
&&
前一个命令执行成功,再执行下一个命令
||
前一个命令执行失败了再执行下一个命令,前一个命令执行成功则不执行下一个命令
!
1.在bash中取反
Linux核心命令 ls命令 列出文件夹中的内容
1 2 3 4 5 6 7 8 9 10 11 12 ls 可选参数 可选的文件夹对象 -a all的意思,显示出所有的文件内容包括隐藏的 -l 详细的输出文件夹中内容 -h 以人类可阅读的形式输出文件大小 --full-time 以完整的时间格式输出 -t 根据文件最后修改的时间进行排序 -F 在不同的文件结尾输出不同的特殊符号(/代表文件目录,*代表的是可执行的文件,以@结尾的就是软连接,快捷方式,结尾什么都没有的为普通文件) -d 显示文件夹本身的信息部署出其中的内容 -r reverse逆转排序 -S 针对文件大小进行排序,默认是从大到小排序 -i 显示出文件的inode信息(相当于文件的身份证号,存储了文件的元信息,文件的大小,位置,权限等)
mkdir命令 1 2 3 4 5 6 7 make directory 创建文件目录 mkdir 文件目录名 -p 递归创建文件目录 bash脚本 跟随bash脚本命令创建多个前缀名相同的文件目录 eg:mkdir qinhuai{1..50} 即创建以qinhuai为前缀名的50个文件目录
touch命令 1 2 3 4 5 6 7 8 9 10 11 touch [选项] 文件 作用: 1.创建普通文件 2.修改文件的时间 touch {连续的数字或字母,1..10,a..z} 创建多个文件序列 -c, --no-create 不创建任何文件 -t STAMP 使用[[CC]YY]MMDDhhmm[.ss] 格式的时间替代当前时间 eg:touch -t 09062244 文件名 即文件的时间修改为了9月6日22时44分 -r, --reference=文件 使用指定文件的时间属性替代当前文件时间
cp命令 1 2 3 4 5 6 7 8 9 10 copy 复制 cp [选项] 源文件 目标目录 cp [选项] -t 源文件 目标文件 将源文件复制到目标文件,或将多个源文件复制到目标目录 -r 递归式复制目录,复制目录下的所有层级的子目录及文件 -p复制时保持属性不变 -d 复制的时候保持软连接(即快捷方式) -p 继承所有权,时间戳,复制文件时保持源文件的权限、时间属性 -i 覆盖前询问提示 -a 等同于-pdr
mv命令 1 2 3 4 5 6 7 8 9 mv命令就是move的缩写,作用是移动或是重命名文件 mv [选项] [-t] 源文件 目标文件 mv [选项] [-t] 源文件 目标目录 mv [选项] 旧文件名 新文件名 将源文件重命名为目标文件 -f 覆盖前不询问 -i 覆盖前询问
rm命令 1 2 3 4 5 6 7 8 rm命令就是remove的含义,删除一个或者多个文件,这是Linux系统的重要命令 -f 强制删除,忽略不存在的文件,不提示确认 -i 在删除前确认,一般不加f都会进行删除确认 -r 在删除超哥文件或者递归删除前要求确认 -d 删除空目录 -r 递归删除目录及其内容 -v 详细显示进行的步骤
cat命令 cat命令用于查看纯文本(常用于内容较少时)
cat功能
功能
说明
查看文件内容
cat filename
多个文件合并
cat filename1 filename2 > filename3
非交互式编辑或追加内容
cat >> filename << EOF
清空文本内容
cat /dev/null > filename [/dev/null是Linux系统的黑洞文件]
1 2 3 4 5 6 7 8 9 10 cat [选项] [文件] -A 等价于-vET -e 等价于-vE -t 等价于-vT -v 使用^和M-引用,除了LFD和TAB之外 -E 在每行结束处显示$ -T 将跳格字符显示为^I -n 对输出的所有行编号 -s 不输出多行空行
eg:
1 2 3 4 5 6 7 8 9 10 1.查看文本内容,以及功能参数 cat test1 2.对非空行显示行号 cat -b test1 3.对所有行显示行号 cat -n test1 4.在每行结尾加上$符号 cat -n -E test1 5.减少空行数量,多个空行减为1个空行 cat -s test1
cat命令合并多个文件
1 2 合并多个文件内容,写入到新的文件中 cat test1 test2 > ./test3
cat非交互式的写入文件内容
1 2 3 4 5 cat >> 文件名 << EOF 内容 内容 内容 EOF
cat清空文件
1 2 3 4 5 6 1.直接清空文件,会留下一个空行 echo > test 2.直接清空文件,空行也不会留下 > test1 3.利用cat读取一个黑空洞文件进行清空 cat /dev/null > test
tac命令 于cat命令查看文件结果相反,cat命令输出结果从首行开始输出一直到末尾行,而tac命令则是从末尾行开始输出一直到首行。
more less命令 分屏查看文件内容的命令
1 2 3 4 5 more 文件名,less命令同理 按下enter键下一行 空格键是向下滚动一个屏大小 =显示当前行号 按下q退出more
head tail命令 head用于查看文件开头的n行
1 2 3 4 5 6 7 8 9 10 11 12 head -数字 文件名 不加数字默认显示前十行 eg: head -5 /etc/passwd [root@RockyLinux systemd]# head -5 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin -c 参数,指定字符数量,显示字符数 head -c 5 文件名 输出这个文件内容的5个字符
tail默认从后向前看10行,也可以用-数字指定显示行数
1 2 3 4 5 6 7 8 9 10 tail -数字 文件名 -f 实时刷新文件内容变化 -F 不断打开文件,通常与-f一起使用,用于还未创建的文件监测 eg:tail -5 /etc/passwd [root@RockyLinux ~]# tail -5 /etc/passwd rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin pipewire:x:990:989:PipeWire System Daemon:/run/pipewire:/usr/sbin/nologin geoclue:x:989:988:User for geoclue:/var/lib/geoclue:/sbin/nologin flatpak:x:988:987:Flatpak system helper:/:/usr/sbin/nologin clevis:x:987:986:Clevis Decryption Framework unprivileged user:/var/cache/clevis:/usr/sbin/nologin
cut命令 cut - 在文件的每一行中提取片段
在每个文件FILE的各行中,把提取的片段显示在标准输出
1 2 3 4 5 6 7 8 9 10 cut [参数] [数值区域] 文件 -b 以字节为单位分割 -n 取消分割多字节字符,与-b一起使用 -c 以字符为单位 -d 自定义分隔符,默认以tab为分隔符 -f 与-d一起使用,指定显示哪个区域 N 第N个字节,字符或字段,从1计数起 N- 从第N个字节,字符或字段直至行尾 N-M 从第N到第M(并包括第M)个字节,字符或字段 -M 从第1到第M(包括第M)个字节,字符或字段
eg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1.截取每一行的第4个字符 cut -c 4 test1 2.截取4到6个字符 cut -c 4-6 test1 3.截取第5和第7个字符 cut -c 5,7 test1 4.截取一个范围的字符,如第4个到结尾 cut -c 4- test1 5.截取一个范围的字符,如开头到第六个字符 cut -c -6 test1 6.指定分隔符号进行截取 cut -d "分隔符号" -f 区域范围 文件名 找出第三个区域的内容 cut -d ":" -f 3 /etc/passwd 找出开头到第三个区域的内容 cut -d ":" -f -3 /etc/passwd
sort命令 sort命令将输入的文件内容按照规则排序,然后输出结果。
1 2 3 4 5 6 7 sort [选项] [文件] -b 忽略前导的空白区域 -n 根据字符串数值比较 -r 逆序输出排序结果 -u 配合-c,严格校验排序;不配合-c则只输出一次排序结果 -t 使用指定的分隔符代替非空格到空格的转换 -k 在位置1开始一个key,在位置2终止(默认为行尾)
eg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1.对文件第一个字符进行排序,默认从小到大 sort -n filename 2.对排序结果反转,从大到小排序 sort -n -r filename 3.对排序结果去重 sort -u filename 4.指定分隔符号,指定区域从小到大进行排序,以ip地址列表为例 sort -t "." -n -k1,1n -k2,2n -k3,3n -k4,4n ip.txt [root@RockyLinux ~]# sort -t "." -n -k3,3n -k4,4n ip.txt 10.0.0.1 10.0.0.3 10.0.0.11 10.0.0.18 10.0.0.56 10.0.0.121 10.0.0.234 10.0.1.20
uniq命令 uniq命令可以输出或者忽略文件中的重复行,常与sort排序结合使用
1 2 3 4 5 6 uniq [选项] filename 从输入文件或者标准输入筛选相邻的匹配行并写入到输出或者标准输出 不附加任何选项时匹配行将在首次出现处被合并。 -c 在每行前加上相应行目出现次数的前缀编号 -d 只输出重复的行 -u 只显示出现过一次的行
eg:
1 2 3 4 5 6 7 8 9 10 1.去除连续的重复行 uniq test1 2.结合sort使用,去重更精准 sort -n test1 | uniq 3.统计每一行重复次数 sort -n test1 | uniq -c 4.只找出文件中重复行,且统计出现次数 sort -n test1 | uniq -d -c 5.找出只出现过一次的行 sort -n test1 | uniq -c -u
wc命令 wc命令用于统计文件的行数、单词、字节数
1 2 3 4 5 -c 打印字节数 -m 打印字符数 -l 打印行数 -L打印最长行的长度 -w 打印单词数
eg:
1 2 3 4 5 6 7 8 9 10 11 1.统计文件的行数 wc -l test1 2.统计单词的数量 wc -w filename 3.统计字符数量 wc -m filename 统计字符数量时会发现统计的数量会比真实的字符数多1,那是因为在统计时将每行末尾的$符号算入了。 4.输出最长行的字符数 wc -L filename 5.统计用户登录数量 who | wc -l
tr命令 tr命令从标准输入中替换、所见或删除字符,将结果写入到标准输出。
1 2 3 4 5 6 7 8 9 10 11 tr [选项] SET1 [SET2] 字符集1:指定要转换或删除的原字符集 当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集 但执行删除操作时,不需要参数“字符集2” 字符集2:指定要转换成的目标字符集 -c 取代所有不属于第一字符集的字符 -d 删除所有术语第一字符集的字符 -s 把连续重复的字符以单独一个字符表示 -t 先删除第一字符集较第二字符集多出的字符
stat命令 stat命令用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细。
1 2 3 4 5 6 stat [选项] [参数] -L 跟随链接 -f 显示文件系统状态而非文件状态 # -c 使用指定输出格式代替默认值,每用一次指定格式换一新行 -t 使用简洁格式输出
find命令 find命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。
如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。
并且将查找到的子目录和文件全部进行显示。
1 2 3 4 find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression] find 处理符号链接 要查找的路径 参数 限定条件 执行动作 find -H -L -P PATH options tests actions
1 2 3 4 5 6 find 查找目录和文件 find 路径 -命令参数 [输出形式] 参数说明: 路径:告诉find在哪去找
参数
解释
pathname
要查找路径
options选项
-maxdepth
<目录层级>:设置最大目录层级
-mindepth
<目录层级>:设置最小目录层级
tests模块
-atime
按照文件访问access的时间查找,单位是天
-ctime
按照文件的改变change状态来查找文件,单位是天
-mtime
根据文件修改modify时间查找文件【最常用】
-name
按照文件名字查找,支持[* ? [] 通配符 ]
-group
按照文件的所属组查找
-perm
按照文件的权限查找
-size n[c w b k M G]
按照文件的大小为n个后缀决定的数据块。
-type 查找某一类型文件
b - 块设备文件
-user
按照文件属性主来查找文件
-path
配合-prune参数排除指定目录
Actions模块
-prune
使find命令不在指定的目录寻找
-delete
删除找出的文件
-exec或-ok
-print
将匹配的结果标准输出
-ok
对后续执行的操作进行询问
OPERATORS
!
取反
-a -o
取交集、并集,作用类似&&和\
xargs命令 xargs又称管道命令,构造参数简单等。
是给命令传递参数的一个过滤器,也是组合多个命令的一个工具他把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理。
简单的说就是把其他命令的给它们的数据传递给它后面的命令作为参数。
1 2 3 4 5 6 7 8 9 10 -d 为输入指定一个定制的分割符,默认分隔符是空格 -i 用{}代替传递的数据 -I string 用string来代替传递的数据-n[数字] 设置每次传递几行数据 -n 选项限制单个命令行的参数个数 -t 显示执行详情 -p 交互模式 -P n 允许的最大线程数量为n -s [大小] 设置传递参数的最大字节数(小于131072字节) -x 大于 -s 设置的最大长度结束 xargs命令执行 -0 --null项用null分割,而不是空白,禁用引号和反斜杠处理
rpm命令 1 2 3 4 5 6 7 8 9 rpm 命令: rpm [options] [package_file] # i表示安装 v显示安装的详细过程 h以进度条显示,每个 安装软件的命令格式 rpm -ivh filename.rpm 升级软件的命令格式 rpm -Uvh filename.rpm 卸载软件的命令格式 rpm -e filename.rpm 查询软件描述信息的命令格式 rpm -qpi filename.rpm 列出软件文件信息的命令格式 rpm -qpl filename.rpm 查询文件属于哪个rpm的命令格式 rpm -qf filename
vim vim使用 所有的Unix Like系统都会内建vi文本编辑器,其他文本编辑器则比一定会存在。但目前我们使用较多的是vim文本编辑器。vim具有程序编辑的能力,可以主动的以字体高亮颜色辨别语法的正确性,方便程序设计。
vim是vi发展来的一个文本编辑器,代码补充、编译及错误跳转等方便编程的功能特别丰富,在程序员中广泛被使用。
vi/vim共分为三种编辑模式,分别是命令模式,输入模式和底线命令模式。
vim工作模式进入方式:
命令模式:进入vim默认的模式
输入模式:一般按i键进入或者是a、o
底线命令模式:按下冒号(’:’)之后进入到的模式
vim工作流程如图
vim快捷键 命令模式下:
光标的移动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 h:光标向左,j:光标向下,k:光标向上,l:光标向右。 除这四个字母移动光标外,还有键盘方向键对光标进行移动。 ↑:光标向上,↓:光标向下,←:光标向左,→:光标向右。 w:移动到下一个单词 b:移动到上一个单词 数字0:移动到行首 字符$:移动到行尾 g:内容的开头 G:内容的结尾 H:移动到屏幕的开头 M:移动到屏幕的中间 L:移动到屏幕的结尾
移动、查找、替换
1 2 3 4 5 6 7 8 9 /要查找的内容 向下查找,按n键继续向下查找 ?要查找的内容 向上查找,按n键继续向上查找 :n1,n2 co n3 将从n1行到n2行之间(包括n1,n2行本身)的所有文本复制到n3行之下 :n1,n2 m n3 将从n1行到n2行之间(包括n1,n2行本身)的所有文本移动到到n3行之下 :n1,n2 d 删除从n1行到n2行之间(包括n1,n2行本身)的所有文本 :s/old/new 将当前行中查找到的第一个字符“old”替换为“new” :s/old/new/g 将当前行中查找到的所有字符“old”替换为“new” :n1,n2 s/old/new/g 将n1到n2行中查找到的所有字符“old”替换为“new” :%s/old/new/g 将整个文件范围内的所有字符“old”替换为“new”
复制、粘贴、删除
1 2 3 4 5 6 7 8 9 输入yy:复制光标所在行的内容 输入nyy:复制包括光标所在行及下边的n行内容 输入p:粘贴复制的内容 输入dd:删除光标当前所在行的内容 输入ndd:删除包括光标所在行及下边的n行内容 输入D:删除光标当前位置到行尾的内容 输入x:删除光标当前字符,向后删除 输入X:删除光标当前字符,向前删除 输入u:撤销上一步的动作
快捷操作
1 2 3 4 5 输入C:删除光标所在位置到行尾的内容并进入编辑模式 输入o:在当前光标下一行开始编辑 输入O:在当前光标上一行开始编辑 输入A:快速进入光标所在行的行尾并进入编辑模式 输入ZZ:快速保存退出
批量快捷操作
1 2 3 4 5 6 7 快捷删除 1.输入Ctrl + v 进入可视块模式 2.用上下左右命令选择操作的的块 3.选中快后,输入d键删除块内容 快捷插入多行 4.选中块后,输入大写的I,进行写代码 5.按下esc两次,会生成多行代码
Linux文件属性与管理 文件或目录属性主要包括:
索引节点,inode
文件类型
文件权限
硬链接个数
归属的用户和用户组
最新修改时间
tar命令 tar命令在Linux系统里,可以实现对多个文件进行压缩、打包、解包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 tar [选项] 压缩后的文件名 要压缩的内容 -A 新增文件到已存在的备份文件 -B 设置区块大小 -c 建立新的备份文件 -C <目录> 这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项 -d 记录文件的差别 -x 从备份文件中还原文件 -t 列出备份文件的内容 -z 通过gzip指令处理备份文件 -Z 通过compress指令处理备份文件 -f <备份文件> 指定备份文件 -v 显示指令执行的过程 -r 添加文件到已压缩的文件 -u 添加改变了和现有的文件到已经存在的压缩文件 -j 支持bzip2解压文件 -l 文件系统边界设置 -k 保留原有文件不覆盖 -m 保留文件不被覆盖 -w 确认压缩文件的正确性 -p 用原来的权限还原文件 --exclude 排除某个文件进行解压缩 -h 将它们所指向的文件归档并输出
1 2 3 4 5 1.常用打包命令 tar -zcvf 包名.tar.gz 要打包的内容 2.常用解压缩命令,需要解压缩到指定路径即后边跟上目录路径,若要单独解压包中的某个文件直接在包名的后边跟上路径即可 tar -zvxf 包名.tar.gz [-C] [路径] 3.不调用gzip则无需加上z参数,打包好的文件名则不带'.gz'
gzip命令 gzip通过压缩算法lempel-ziv将文件压缩为较小文件,节省60%以上的存储空间,以及网络传输速率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 gzip [选项] [参数] -a 使用ASCII文字模式 -c 把解压后的文件输出到标准输出设备 -d 解开压缩文件 -f 强制压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接 -l 列出压缩文件的相关信息 -L 显示版本与版权信息 -n 压缩时不保存原来的文件名称及时间戳 -N 压缩文件时保存原来的文件名称及时间戳 -q 不显示警告信息 -r 递归处理,将指定目录下的所有文件及子目录一并处理 -S 更改压缩字尾字符串 -t 测试压缩文件是否正确无误 -v 显示指令执行过程 -数字 压缩效率是一个1-9的数值,预设值为“6”,指定愈大的数值,压缩效率就会愈高 --best 此参数的效果和指定“-9”参数相同 --fast 此参数的效果和指定“-1”参数相同
zip命令 zip命令:是一个应用广泛的跨平台的压缩工具,压缩文件后的后缀为zip文件,还可以压缩文件夹
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 zip 压缩文件名 要压缩的内容 -A 自动解压文件 -c 给压缩文件加注释 -d 删除文件 -F 修复损坏文件 -k 兼容DOS -m 压缩完毕后,删除源文件 -q 运行时不显示信息处理信息 -r 处理指定目录和指定目录下的使用子目录 -v 显示信息的处理信息 -x “文件列表”压缩时排除文件列表中指定的文件 -y 保留符号链接 -b <目录> 指定压缩到的目录 -i <格式> 匹配格式进行压缩 -t <日期> 指定压缩文件的日期 -<压缩率> 指定压缩率
unzip命令用于解压
1 2 -l 显示压缩文件内所包含的文件 -d <目录> 指定文件解压缩后所要存储的目录
Linux用户管理 UID,相当于用户的身份证号
GID,相当于一个家庭户口本的编号
在Linux系统中,用户拥有自己的UID身份账号且唯一。
在Linux中UID为0,就是超级用户,如果要设置管理员用户,可以改UID为0,建议使用sudo
普通用户UID为1~999 Linux安装的服务程序都会创建独有的用户负责运行。
普通用户UID从1000开始:由管理员创建,范围:1000~60000。
用户信息配置文件 在/etc/passwd文件中
1 2 root :x :0 :0 :root :/root :/bin/bash 用户名 密码 UID GID 用户注释 用户家目录 用户使用的解释器
用户管理的命令
命令
作用
useradd
创建用户
usermod
修改用户信息
userdel
删除用户及配置文件
passwd
更改用户密码
chpasswd
批量更新用户密码
chage
修改用户密码属性
id
查看用户UID、GID、组信息
su
切换用户
sudo
用root身份执行命令
visudo
编辑sudoers配置文件
useradd命令 useradd命令用于Linux中创建的新的系统用户
useradd可用来建立用户账号,账号建好之后,再用passwd设定账号的密码,而可用userdel删除账号。
使用useradd指令所建立的账号,实际上是保存在/etc/passwd文本文件中。
1 2 3 4 5 6 7 8 9 10 11 12 13 -c<备注> 加上备注文字,备注文字会保存在passwd的备注栏位中 -d<登入目录> 指定用户登入时的起始目录 -D 变更预设值 -e<有效期> 指定账号的有效期限 -f<缓冲天数> 指定在密码过期后多少天即关闭该账号 -g<群组> 指定用户所属的群组 -G<群组> 指定用户所属的附加群组 -m 自动建立用户的登入目录 -M 不要自动建立用户的登入目录 -n 取消建立以用户名称为名的群组 -r 建立系统账号 -s<shell> 指定用户登入后所使用的shell -u<uid> 指定用户id
usermod命令 usermod命令用于修改系统已存在的用户信息,只能修改未使用中的用户。
1 2 3 4 5 6 7 8 9 10 11 12 13 usermod [选项] [参数] -c<备注> 修改用户账号的备注文字 -d<登入目录> 修改用户登录时的目录 -e<有效期> 修改账号的有效期限 -f<缓冲天数> 修改在密码过期后多少天即关闭该账号 -g<群组> 修改用户所属的用户组 -G<群组> 修改用户所属的附加群组 -l<账号名称> 修改用户账号名称 -L 锁定用户密码,使密码无效 -s<shell> 修改用户登陆后使用的shell -u<uid> 修改用户ID -U 解除密码锁定
userdel 删除用户与相关文件
建议在生产环境中注释/etc/passwd用户信息而非直接删除用户
1 2 3 4 userdel [选项] [参数] -f 强制删除用户,即使用户当前已登录 -r 删除用户的同时,删除与用户相关的所有文件
groupadd命令 groupadd命令用于创建一个新的工作组,新工作组的信息将被添加到系统文件中。
批量更新密码命令 1 2 3 4 5 1.查看当前机器的用户信息 tail /etc/passwd 2.批量修改密码,ctrl + d结束输入 chpasswd 用户名:修改的密码
文件权限 chattr命令 chattr命令用于更改文件的扩展属性,比chmod更改的rwx权限更为底层。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 参数: a 只能向文件中添加数据,不得删除 -R 递归更改目录属性 -V 显示命令执行过程 模式 + 增加参数 - 移除参数 = 更新为指定参数 A 不让系统修改文件最后访问时间 a 只能追加文件数据,不得删除 i 文件不能被删除、改名、修改内容 增加权限使用chattr +参数 文件 取消权限使用chattr -参数 文件
正则表达式 由一类特殊字符及文本字符所编写的模式,其中有些字符不表示其字面意义,而是用于表示控制或通配的功能。
分两类:
意义
通过特殊符号的辅助,可以让Linux管理员快速过滤、替换、处理所需要的字符串、文本,让工作高效。
通常Linux运维工作,都是面临大量带有字符串的内容,如:
且此类字符串内容常会有特定的需要,查找出符合工作需要的特定字符,因此正则表达式就出现了。
正则表达式是一套规则和方法
正则工作时以单位进行,一次处理一行
正则表达式化繁为简,提高工作效率
Linux仅受三剑客(sed、awk、grep)支持,其他命令无法使用
正则表达式应用非常广泛,应用在如python、Java、Perl等,Linux下普通命令无法使用正则表达式,只能使用三剑客。
通配符大部分普通命令都支持的,用于查找文件或目录,而正则表达式是通过三剑客命令在文件(数据流)中过滤内容的。
Linux命令三剑客 文本处理工具,均支持正则表达式引擎
grep:文本过滤工具,(模式pattern)工具,擅长单纯的查找或匹配文本内容。
sed:stream editor,流编辑器;文本编辑工具
awk:Linux的文本报告生成器(格式化文本),Linux上是gawk
正则表达式分类 Linux三剑客主要分为两类
基本正则表达式(BRE、basic regular expression)
扩展正则表达式(ERE、extended regular expression)
1 ERE在BRE基础上,增加上了() {} ? + |等字符
基本正则表达式BRE集合
符号
作用
^
尖叫号,用于模式的最左侧,如”^词”,匹配以词开头的行
$
dollar符,用于模式的最右侧,如”词$”,匹配以词结尾的行
^$
组合符,表示空行
.
匹配任意一个且只有一个字符,不能匹配空行
\
转义字符,让特殊含义的字符现出原形,还原本意,例如\.代表小数点
*
匹配前一个字符连续出现0次或1次以上,重复0次代表空,即匹配所有内容
.*
组合符,匹配所有内容
^.*
组合符,匹配任意多个字符开头的内容
.*$
组合符,匹配以任意多个字符结尾的内容
[abc]
匹配[]集合内的任意一个字符,a或b或c,可以写[a-c]
[^abc]
匹配除了^后面的任意字符,a或b或c,^表示对[abc]取反
扩展表达式ERE集合 扩展正则必须用grep -E才能生效
字符
作用
+
匹配前一个字符1次或多次
[:/]+
匹配括号内的”:”或者”/“字符1次或多次
?
匹配前一个字符0次或1次
|
表示或者,同时过滤多个字符串
()
分组过滤,被括起来的内容表示一个整体
a{n,m}
匹配前一个字符最少n次,最多m次
a{n,}
匹配前一个字符最少n次
a{n}
匹配前一个字符正好n次
a{,m}
匹配前一个字符最多m次
1 2 3 4 注意!!! grep命令需要使用参数 -E即可支持正则表达式 egrep不推荐使用,使用grep -E替代 grep不加参数,得在特殊字符前面加"\"反斜杠,识别为正则。
grep命令 全拼:Global search REgular expression Print out the line
作用: 文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本进行匹配检查,打印匹配到的行
模式: 由正则表达式的**元字符及 文本字符所编写出的 过滤条件**
1 2 grep [options] [pattern] file 命令 参数 匹配模式 文件数据
gerp命令是Linux系统中最重要的命令之一,功能是从**文本文件或 管道数据流中筛选匹配的 行和 数据,如果再配合 正则表达式**,功能十分强大,是Linux运维人员必备的命令。
grep命令里的**匹配模式就是你想要找的东西,可以是 普通文字符号,也可以是 正则表达式**。
参数选项
解释说明
-v
排除匹配结果
-n
显示匹配行与行号
-i
不区分大小写
-c
只统计匹配的行数
-E
使用egrep命令
–color=auto
为grep过滤结果添加颜色
-w
只匹配过滤的单词
-o
只输出匹配的内容
-m
最多出现的次数
-l
多文件匹配
eg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1.忽略大小写查找内容,并显示行号 [root@RockyLinux linuxtest]# grep -i -n "root" passwd.txt 1:root:x:0:0:root:/root:/bin/bash 4:ROOT:x:3:4:adm:/var/adm:/sbin/nologin 10:operator:x:11:0:operator:/root:/sbin/nologin 2.统计passwd.txt文件中有多少行root(忽略大小写) [root@RockyLinux linuxtest]# grep -i -c "root" passwd.txt 3 3.找出passwd.txt文件的空行并显示行号 [root@RockyLinux linuxtest]# grep -n "^$" passwd.txt 5: 12: 16: 21: 23: 24: 26: 27: 28: 4.找出passwd.txt文件中没有空行及注释行的内容并显示行号 grep -v "^#" passwd.txt | grep -v -n "^$"
基本正则表达式grep实战 实战文件内容如下
**^**符号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1.找出所有以m开头的行 [root@RockyLinux linuxtest]# grep -i -n "^m" grep.txt 5:My blog site is http://blog.7464824.top 2.输出所有以i开头的行 [root@RockyLinux linuxtest]# grep -i -n "^i" grep.txt 1:I am qinhuai 2:I'm studing Linux 3:I love Cloud Computing 7:I'm a blog creator 3.找出所有的空行 [root@RockyLinux linuxtest]# grep -n "^$" grep.txt 4: 6: 8: 10: 11:
**$**符号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 1.输出所有以r结尾的行 [root@RockyLinux linuxtest]# grep -i -n "r$" grep.txt 7:I'm a blog creator 2.输出所有以p结尾的行 [root@RockyLinux linuxtest]# grep -i -n "p$" grep.txt 5:My blog site is http://blog.7464824.top 3.只输出以g结尾的行 [root@RockyLinux linuxtest]# grep -i -n -o "g$" grep.txt 3:g 4.只输出有g结尾的单词的行 [root@RockyLinux linuxtest]# grep -i -n -o "g.*$" grep.txt 2:g Linux 3:g 5:g site is http://blog.7464824.top 7:g creator 5.只输出有c的单词的行 [root@RockyLinux linuxtest]# grep -i -n "^.*c" grep.txt 3:I love Cloud Computing 7:I'm a blog creator 9:Nice to meet you!!! 6.输出以"."结尾的行,需要使用到转义字符。 [root@RockyLinux linuxtest]# grep -n "\.$" grep.txt 3:I love Cloud Computing. 7:I'm a blog creator.
值得注意的是,再Linux平台下,所有文件的结尾都一个$符,使用到以”.”结尾的行时,用到”.$”进行匹配的话,则会显示所有行,前面有提到”.”符号用于**匹配任意一个且只有一个字符,不能匹配空行,这时候就需要用到 \**转义字符。
**^$**组合符 1 2 3 4 5 6 7 找出文件的空行并显示行号 [root@RockyLinux linuxtest]# grep -n "^$" grep.txt 4: 6: 8: 10: 11:
**.**符号 **.**点表示任意一个字符,有且只有一个,不包含空行
1 2 3 4 5 6 7 [root@RockyLinux linuxtest]# grep -i -n "." grep.txt 1:I am qinhuai 2:I'm studing Linux 3:I love Cloud Computing. 5:My blog site is http://blog.7464824.top 7:I'm a blog creator. 9:Nice to meet you!!!
匹配出”.c”,找出任意一个两位字符,包含c
1 2 3 4 [root@RockyLinux linuxtest]# grep -i -n ".c" grep.txt 3:I love Cloud Computing. 7:I'm a blog creator. 9:Nice to meet you!!!
**\**转义字符 1 2 3 4 5 找出文中所有的"." [root@RockyLinux linuxtest]# grep -n "\." grep.txt 3:I love Cloud Computing. 5:My blog site is http://blog.7464824.top 7:I'm a blog creator.
*****符号 1 2 3 4 5 6 7 8 9 10 找出前一个字符0次或多次,找出文中出现"i"的0次或多次。 [root@RockyLinux linuxtest]# grep -n -o "i*" grep.txt 1:i 1:i 2:i 2:i 3:i 5:i 5:i 9:i
**.***组合符 .表示任意一个字符,*表示匹配前一个字符0次或多次,因此放一起代表匹配所有内容,以及空格
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@RockyLinux linuxtest]# grep -n ".*" grep.txt 1:I am qinhuai 2:I'm studing Linux 3:I love Cloud Computing. 4: 5:My blog site is http://blog.7464824.top 6: 7:I'm a blog creator. 8: 9:Nice to meet you!!! 10: 11: [root@RockyLinux linuxtest]# grep -n ".*e" grep.txt 3:I love Cloud Computing. 5:My blog site is http://blog.7464824.top 7:I'm a blog creator. 9:Nice to meet you!!!
[abc]中括号中括号表达式,[abc]表示匹配中括号中任意一个字符a或b或c,常见形式如下:
[a-z]匹配所有小写单个字母
[A-Z]匹配所有单个大写字母
[a-zA-Z]匹配所有的单个大小写字母
[0-9]匹配所有单个数字
[a-zA-Z0-9]匹配所有数字和字母
1 2 3 4 5 6 7 8 1.匹配文件中所有除0-5以外的内容 [root@RockyLinux linuxtest]# grep -n "[a-zA-Z0-5]" grep.txt 1:I am qinhuai 2:I'm studing Linux 3:I love Cloud Computing. 5:My blog site is http://blog.7464824.top 7:I'm a blog creator. 9:Nice to meet you!!!
参数-o 使用”-o”选项,可以只显示被匹配到的关键字,而不是将整行的内容都输出。
显示文件中有多少个字符a
1 2 [root@RockyLinux linuxtest]# grep -o "a" grep.txt | wc -l 4
[^abc]中括号取反[^abc]或[^a-c]这样的命令,”^”符号在中括号中第一位表示排除,就是排除字母a或b或c。
出现在中括号中的尖角号^表示取反
找出除了小写字母以外的字符
1 2 3 4 5 6 7 [root@RockyLinux linuxtest]# grep -n "[^a-z]" grep.txt 1:I am qinhuai 2:I'm studing Linux 3:I love Cloud Computing. 5:My blog site is http://blog.7464824.top 7:I'm a blog creator. 9:Nice to meet you!!!
扩展正则表达式grep实战 次数使用grep -E进行实践扩展正则,egrep官网已经弃用。
+符**+**号表示匹配前一个字符1次或多次,必须使用grep -E扩展正则
1 2 3 4 5 6 7 [root@RockyLinux linuxtest]# grep -i -E "i+" grep.txt I am qinhuai I'm studing Linux I love Cloud Computing. My blog site is http://blog.7464824.top I'm a blog creator. Nice to meet you!!!
?符匹配前一个字符0次或1次
找出文件中包含ain或者in的行
1 2 3 4 [root@RockyLinux linuxtest]# grep -E "a?in" grep.txt I am qinhuai I'm studing Linux I love Cloud Computing.
|符竖线**|**在正则中是或者的意思
1 2 3 找出系统中的txt文件,且名字包含a或b的字符 [root@RockyLinux linuxtest]# find / -maxdepth 3 -name "*.txt" | grep -i -E "a|b" /root/linuxtest/passwd.txt
()小括号将一个或多个字符捆绑在一起,当作一个整体进行处理;
小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体
括号()内的内容可以被后面的"\n"正则引用,表示引用第几个括号的内容
\1:表示从左侧起,第一个括号中的模式所匹配到的字符。
\2:从左侧起,第二个括号中的模式所匹配到的字符
1 2 3 4 找出包含good和glad的行 [root@RockyLinux linuxtest]# grep -E "g(oo|la)d" test.txt glad good
分组之后向引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@RockyLinux linuxtest]# cat >>lovers.txt<< EOF > I like my lover. > I love my lover. > He likes his lovers. > He love his lovers. > > EOF [root@RockyLinux linuxtest]# grep -E "(l..e).*\1" lovers.txt I love my lover. He love his lovers. [root@RockyLinux linuxtest]# grep -E "(r..t).*\1" /etc/passwd root:x:0:0:root:/root:/bin/bash
{n,m}匹配次数重复前一个字符 的次数,可以通过-o参数显示明确的匹配过程。
{n,m}:最少出现n次,最多出现m次
{n,}:最少出现n次
{,m}:最多出现m次
{n}:正好出现n次
1 2 3 4 [root@RockyLinux linuxtest]# grep -E "o{4,}" grep.txt oooo oooooo oodoodooodoooo
sed命令 注意: sed和awk命令使用单引号,双引号有特殊解释
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具
常用功能包括结合正则表达式对文件实现增删改查,其中查询的功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)。
1 sed [选项] [sed内置命令字符] [输入文件]
选项
参数选项
解释
-n
取消默认sed的输出,常与sed内置命令p一起用
-i
直接将修改结果写入文件,不用-i,sed修改的是内存数据
-e
多次编辑,不需要管道符
-r
支持正则扩展
sed的内置命令字符用于对文件进行不同的操作功能,如对文件增删改查。
sed常用内置命令字符:
sed的内置命令字符
解释
a
append,对文本追加,在指定行后面添加一行/多行文本
d
Delete,删除匹配行
i
insert,表示插入文本,在指定行前添加一行/多行文本
p
Print,打印匹配行的内容,通常p与-n一起使用
s/正则/替换内容/g
匹配正则内容,然后替换内容(支持正则),结尾g代表全局匹配
sed匹配范围
范围
解释
空地址
全文处理
单地址
指定文件某一行
/pattern/
被模式匹配到的每一行
范围区间
10,20 10到20行, 10,+5第10行向下5行,/pattern1/,/pattern2/
步长
1~2,表示1、3、5、7、9行,2~2两个步长,表示2、4、6、8,偶数行
sed案例 数据准备
1 2 3 4 5 6 7 8 [root@RockyLinux sed]# cat >>sedtest.txt<< EOF > My name is qinhuai > I study Linux > I like play computer games. > My qq is 182604. > My blogsite is http://blog.7464824.top. > EOF
eg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 1.输出文件第2,3行的内容 [root@RockyLinux sed]# sed -n '2,3p' sedtest.txt I study Linux I like play computer games. 2.过滤含有linux的字符串行 sed可以实现grep的过滤效果,必须把要过滤的内容放在双斜杠中,精准匹配,过滤字符要与文本内容中的一致,区分大小写 [root@RockyLinux sed]# sed -n '/Linux/p' sedtest.txt I study Linux 3.删除含有game的行 注意sed想要修改文本内容还得用-i参数。 [root@RockyLinux sed]# sed -n '/game/p' sedtest.txt I like play computer games. [root@RockyLinux sed]# sed -i '/game/d' sedtest.txt [root@RockyLinux sed]# cat sedtest.txt My name is qinhuai I study Linux My qq is 182604. My blogsite is http://blog.7464824.top. [root@RockyLinux sed]# 4.删除第5行到结尾 [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 My qq is 182604. 4 My blogsite is http://blog.7464824.top. 5 我是要被删除的行1 6 我是要被删除的行2 7 我是要被删除的行3 8 我是要被删除的行4 9 我是要被删除的行5 10 我是要被删除的行6 [root@RockyLinux sed]# sed -i '5,$d' sedtest.txt [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 My qq is 182604. 4 My blogsite is http://blog.7464824.top. 5.将文件中的My全部替换为His s内置符配合g,代表全局替换,中间的"/"可以替换为"#@/"等 [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 My qq is 182604. 4 My blogsite is http://blog.7464824.top. [root@RockyLinux sed]# sed -i 's/My/His/g' sedtest.txt [root@RockyLinux sed]# cat -n sedtest.txt 1 His name is qinhuai 2 I study Linux 3 His qq is 182604. 4 His blogsite is http://blog.7464824.top. 6.替换所有的His为My,同时换掉QQ号为666666 sed -i -e 's/His/My/g' -e 's/182604/666666/g' sedtest.txt [root@RockyLinux sed]# cat -n sedtest.txt 1 His name is qinhuai 2 I study Linux 3 His qq is 182604. 4 His blogsite is http://blog.7464824.top. [root@RockyLinux sed]# sed -i -e 's/His/My/g' -e 's/182604/666666/g' sedtest.txt [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 My qq is 666666. 4 My blogsite is http://blog.7464824.top. 7.在文件的第二行追加内容a字符功能,写入到文件,得加-i [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 My qq is 666666. 4 My blogsite is http://blog.7464824.top. [root@RockyLinux sed]# sed -i '2a .' sedtest.txt [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 . 4 My qq is 666666. 5 My blogsite is http://blog.7464824.top. 8.多行追加,需要中间使用换行符`\n` [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 . 4 My qq is 666666. 5 My blogsite is http://blog.7464824.top. [root@RockyLinux sed]# sed -i '3a 追加内容1\n追加内容2' sedtest.txt [root@RockyLinux sed]# cat -n sedtest.txt 1 My name is qinhuai 2 I study Linux 3 . 4 追加内容1 5 追加内容2 6 My qq is 666666. 7 My blogsite is http://blog.7464824.top.
sed配合正则表达式实战 取出Linux的IP地址 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1.去头去尾法,交给管道符一次去头,一次去尾 思路: 先取出第二行 [root@RockyLinux sed]# ifconfig ens2 | sed -n '2p' inet 192.168.100.100 netmask 255.255.255.0 broadcast 192.168.100.255 取出第二行之后去掉ip之前的内容 [root@RockyLinux sed]# ifconfig ens2 | sed -n '2p' |sed 's/^.*inet //' 192.168.100.100 netmask 255.255.255.0 broadcast 192.168.100.255 再次处理,去掉ip后面的内容 [root@RockyLinux sed]# ifconfig ens2 | sed -n '2p' | sed 's/^.*inet //' | sed 's/ netmask.*$//' 192.168.100.100 2.-e参数进行多次编辑 [root@RockyLinux sed]# ifconfig ens2 | sed -n -e '2s/^.*inet //' -e '2s/ netm.*$//p' 192.168.100.100
awk命令 awk是一个强大的Linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表的样式。
awk早期在unix上实现,我们所使用的awk是gawk,是GUN awk的意思。
awk更是一门编程语言,支持条件判断、数组、循环等功能。
awk基础 1 2 3 awk [option] 'pattern[action]' file... awk 参数 '条件动作' 文件
Action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作就是print和printf。
awk场景 动作场景 测试数据
1 2 3 4 5 6 7 8 9 10 11 12 [root@RockyLinux awk]# echo qhuai{1..50} | xargs -n 5 | cat > awktest1 [root@RockyLinux awk]# cat awktest1 qhuai1 qhuai2 qhuai3 qhuai4 qhuai5 qhuai6 qhuai7 qhuai8 qhuai9 qhuai10 qhuai11 qhuai12 qhuai13 qhuai14 qhuai15 qhuai16 qhuai17 qhuai18 qhuai19 qhuai20 qhuai21 qhuai22 qhuai23 qhuai24 qhuai25 qhuai26 qhuai27 qhuai28 qhuai29 qhuai30 qhuai31 qhuai32 qhuai33 qhuai34 qhuai35 qhuai36 qhuai37 qhuai38 qhuai39 qhuai40 qhuai41 qhuai42 qhuai43 qhuai44 qhuai45 qhuai46 qhuai47 qhuai48 qhuai49 qhuai50
取出第二列数据
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk '{print $2}' awktest1 qhuai2 qhuai7 qhuai12 qhuai17 qhuai22 qhuai27 qhuai32 qhuai37 qhuai42 qhuai47
我们执行的命令是awk ‘{print $2}’ 文件名,没有使用参数和模式,$2表示输出文本的第二列信息
awk默认以空格为分隔符,且多个空格也识别为以一个空格,作为分隔符
awk是按行处理文件,一行处理完毕,处理下一行,根据用户指定的分隔符去工作,没有指定则默认空格
指定了分隔符后,awk把每一行切割后的数据对应到内置变量
$0:表示整行
$n:表示第n列
$NF:表示当前分割后的最后一列
$(NF-1):表示倒数第二列
awk内置变量
内置变量
解释
$n
指定分隔符后,当前记录的第n个字段
$0
完整的输入记录
FS
字段分隔符,默认是空格
NF(Number of fields)
分割后,当前行一共有多少个字段
NR(Number of records)
当前记录数,行数
更多内置变量可以man手册查看
man awk
一次性输出多列,可自定义
awk,必须外层单引号,内层双引号
内置变量$1、$2都不得添加双引号,否则会识别为文本,尽量别加引号
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk '{print $1,$5,$2}' awktest1 qhuai1 qhuai5 qhuai2 qhuai6 qhuai10 qhuai7 qhuai11 qhuai15 qhuai12 qhuai16 qhuai20 qhuai17 qhuai21 qhuai25 qhuai22 qhuai26 qhuai30 qhuai27 qhuai31 qhuai35 qhuai32 qhuai36 qhuai40 qhuai37 qhuai41 qhuai45 qhuai42 qhuai46 qhuai50 qhuai47
输出整行信息
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk '{print "每一行的内容是:"$0}' awktest1 每一行的内容是:qhuai1 qhuai2 qhuai3 qhuai4 qhuai5 每一行的内容是:qhuai6 qhuai7 qhuai8 qhuai9 qhuai10 每一行的内容是:qhuai11 qhuai12 qhuai13 qhuai14 qhuai15 每一行的内容是:qhuai16 qhuai17 qhuai18 qhuai19 qhuai20 每一行的内容是:qhuai21 qhuai22 qhuai23 qhuai24 qhuai25 每一行的内容是:qhuai26 qhuai27 qhuai28 qhuai29 qhuai30 每一行的内容是:qhuai31 qhuai32 qhuai33 qhuai34 qhuai35 每一行的内容是:qhuai36 qhuai37 qhuai38 qhuai39 qhuai40 每一行的内容是:qhuai41 qhuai42 qhuai43 qhuai44 qhuai45 每一行的内容是:qhuai46 qhuai47 qhuai48 qhuai49 qhuai50
awk变量
参数
解释
-F
指定分割字段
-v
定义或修改一个awk内部的变量
-f
从脚本文件中读取awk命令
对于awk而言,变量分为:
内置变量
解释
FS
输入字段分隔符,默认为空白字符
OFS
输出字段分隔符,默认为空白字符
RS
输入记录分隔符(输入换行符),指定输入时的换行符
ORS
输出记录分隔符(输出换行符),输出时指定符号代替换行符
NF
NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量
NR
NR:行号,当前处理的文本行的行号
FNR
FNR:各文件分别计数的符号
FILENAME
FILENAME:当前文件名
ARGC
ARGC:命令行参数的个数
ARGV
ARGV:数组,保存的是命令行所给定的各参数
内置变量 NR、NF、FNR awk的内置变量NR、NF是不用添加$符号的
而**$0 $1 $2 $3...是需要添加 $**符号的
输出每行行号,以及字段总个数
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk -F "#" '{print NR,NF}' awktest1 1 5 2 5 3 5 4 5 5 5 6 5 7 5 8 5 9 5 10 5
输出每行行号,以及指定的列
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk -F "#" '{print NR,$2}' awktest1 1 qhuai2 2 qhuai7 3 qhuai12 4 qhuai17 5 qhuai22 6 qhuai27 7 qhuai32 8 qhuai37 9 qhuai42 10 qhuai47
处理多个文件显示行号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 普通的NR变量,会将多个文件按照顺序排序 [root@RockyLinux awk]# awk -v FS=":" '{print NR,$0}' awktest1 passwd.txt 1 qhuai1:qhuai2:qhuai3:qhuai4:qhuai5 2 qhuai6:qhuai7:qhuai8:qhuai9:qhuai10 3 qhuai11:qhuai12:qhuai13:qhuai14:qhuai15 4 qhuai16:qhuai17:qhuai18:qhuai19:qhuai20 5 qhuai21:qhuai22:qhuai23:qhuai24:qhuai25 6 qhuai26:qhuai27:qhuai28:qhuai29:qhuai30 7 qhuai31:qhuai32:qhuai33:qhuai34:qhuai35 8 qhuai36:qhuai37:qhuai38:qhuai39:qhuai40 9 qhuai41:qhuai42:qhuai43:qhuai44:qhuai45 10 qhuai46:qhuai47:qhuai48:qhuai49:qhuai50 11 root:x:0:0:root:/root:/bin/bash 12 bin:x:1:1:bin:/bin:/sbin/nologin 13 daemon:x:2:2:daemon:/sbin:/sbin/nologin 14 adm:x:3:4:adm:/var/adm:/sbin/nologin 15 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 16 sync:x:5:0:sync:/sbin:/bin/sync 17 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 使用FNR变量,可以分队对文件行数进行计数 [root@RockyLinux awk]# awk -v FS=":" '{print FNR,$0}' awktest1 passwd.txt 1 qhuai1:qhuai2:qhuai3:qhuai4:qhuai5 2 qhuai6:qhuai7:qhuai8:qhuai9:qhuai10 3 qhuai11:qhuai12:qhuai13:qhuai14:qhuai15 4 qhuai16:qhuai17:qhuai18:qhuai19:qhuai20 5 qhuai21:qhuai22:qhuai23:qhuai24:qhuai25 6 qhuai26:qhuai27:qhuai28:qhuai29:qhuai30 7 qhuai31:qhuai32:qhuai33:qhuai34:qhuai35 8 qhuai36:qhuai37:qhuai38:qhuai39:qhuai40 9 qhuai41:qhuai42:qhuai43:qhuai44:qhuai45 10 qhuai46:qhuai47:qhuai48:qhuai49:qhuai50 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
RS RS变量作用是输入分隔符,默认是回车符(enter键)。
我们也可以自定义空格符作为行分隔符,每遇到一个空格符就作换行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 测试数据准备 echo test{1..10} | cat >> awktest2 换行处理 [root@RockyLinux awk]# awk -v RS=" " '{print NR,$0}' awktest2 1 test1 2 test2 3 test3 4 test4 5 test5 6 test6 7 test7 8 test8 9 test9 10 test10 如果将awktest2分成多行,再执行此命令,结果就会出现不同 [root@RockyLinux awk]# xargs -n 4 < awktest2 test1 test2 test3 test4 test5 test6 test7 test8 test9 test10 [root@RockyLinux awk]# xargs -n 4 < awktest2 | cat > awktest3 [root@RockyLinux awk]# awk -v RS=" " '{print NR,$0}' awktest3 1 test1 2 test2 3 test3 4 test4 test5 5 test6 6 test7 7 test8 test9 8 test10 可以看到第四行,第7行与上面的输出结果存在差异,这是因为awk认为空格是分隔符,test4和test8后边没有空格了,因此test4和test5,test8和test9算成了一行
ORS ORS是输出分隔符的意思,awk默认认为,每一行结束了,就得添加回车换行符
ORS变量可以更改输出符
1 2 3 4 [root@RockyLinux awk]# awk -v ORS='@@@\n' '{print NR,$0}' awktest3 1 test1 test2 test3 test4@@@ 2 test5 test6 test7 test8@@@ 3 test9 test10@@@
FILENAME 显示awk正在处理文件的名字
1 2 3 4 [root@RockyLinux awk]# awk '{print FILENAME,$0}' awktest3 awktest3 test1 test2 test3 test4 awktest3 test5 test6 test7 test8 awktest3 test9 test10
ARGC、ARGV ARGV表示的是一个数组,数组中保存的是命令行所给的参数
数组是一种数据类型,如同一个盒子
盒子有他的名字,且内部有N个小格子,标号从0开始
1 2 3 执行awk命令对ARGV数组进行打印时,输出结果是[awk命令,文件1,文件2,。。] [root@RockyLinux awk]# awk 'BEGIN{print ARGV[0],ARGV[1],ARGV[2]}' awktest1 awktest2 awk awktest1 awktest2
自定义变量 顾名思义,就是我们自己定义变量
方法1,-v varName=value
1 2 [root@RockyLinux awk]# awk -v myname="秦淮" 'BEGIN{print "我的名字是"myname}' 我的名字是秦淮
方法2,在程序中定义
1 2 3 4 5 6 [root@RockyLinux awk]# awk 'BEGIN{myself="我的名字是";myname="秦淮";print myself,myname}' 我的名字是 秦淮 [root@RockyLinux awk]# awk 'BEGIN{myself="我的名字是";myname="秦淮";print myself myname}' 我的名字是秦淮 [root@RockyLinux awk]# awk 'BEGIN{myself="我的名字是";myname="秦淮";print myselfmyname}'
可以看到这三种不同的打印变量的方法结果也不相同,添加逗号,之后,变量之间会以空格隔开。空格隔开变量名则打印出来的结果不会空格隔开,而变量名没有进行隔开措施则不会打印出结果或者打印出的结果为空。
方法3,间接引用shell变量
1 2 3 4 5 6 7 8 9 [root@RockyLinux awk]# awk -v myVar=$myself$myname 'BEGIN{print myVar}' 我的名字是秦淮 [root@RockyLinux awk]# awk -v myVar=$myself,$myname 'BEGIN{print myVar}' 我的名字是,秦淮 [root@RockyLinux awk]# awk -v myVar=$myself $myname 'BEGIN{print myVar}' awk: cmd. line:1: 秦淮 awk: cmd. line:1: ^ invalid char '�' in expression [root@RockyLinux awk]# awk -v myVar=$myself+$myname 'BEGIN{print myVar}' 我的名字是+秦淮
awk分隔符 awk的分隔符有两种
输入分隔符,awk默认是空格,空白字符,英文是field separator,变量名是FS
输出分隔符,output field separator,简称OFS
FS输入分隔符 awk逐行处理文本的时候,以输入分隔符为准,把文本切成多个片段,默认符号是空格
当我们处理特殊文本,没有空格的时候,可以自由指定分隔符特点
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk -F "#" '{print $2}' awktest1 qhuai2 qhuai7 qhuai12 qhuai17 qhuai22 qhuai27 qhuai32 qhuai37 qhuai42 qhuai47
除了使用-F选项,还可以使用变量的形式,指定分隔符,使用-v选项搭配,修改FS变量。
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk -v FS="#" '{print $1}' awktest1 qhuai1 qhuai6 qhuai11 qhuai16 qhuai21 qhuai26 qhuai31 qhuai36 qhuai41 qhuai46
OFS输出分隔符 awk执行完命令,默认用空格隔开每一列,这个空格就是awk的默认输出符。
eg:
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk -v FS="#" '{print $1,$3}' awktest1 qhuai1 qhuai3 qhuai6 qhuai8 qhuai11 qhuai13 qhuai16 qhuai18 qhuai21 qhuai23 qhuai26 qhuai28 qhuai31 qhuai33 qhuai36 qhuai38 qhuai41 qhuai43 qhuai46 qhuai48
修改默认分隔符就需要修改OFS的值,也可以使用\t制表符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@RockyLinux awk]# awk -F "#" -v OFS="------" '{print $1,$3}' awktest1 qhuai1------qhuai3 qhuai6------qhuai8 qhuai11------qhuai13 qhuai16------qhuai18 qhuai21------qhuai23 qhuai26------qhuai28 qhuai31------qhuai33 qhuai36------qhuai38 qhuai41------qhuai43 qhuai46------qhuai48 [root@RockyLinux awk]# awk -F "#" -v OFS="\t" '{print $1,$3}' awktest1 qhuai1 qhuai3 qhuai6 qhuai8 qhuai11 qhuai13 qhuai16 qhuai18 qhuai21 qhuai23 qhuai26 qhuai28 qhuai31 qhuai33 qhuai36 qhuai38 qhuai41 qhuai43 qhuai46 qhuai48
awk格式化 前面我们接触到的awk的输出功能,是{print}的功能,只能对文本简单的输出,并不能美化或者修改格式
printf格式化输出 print和print的区别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 要点: 1.其与print命令的最大不同是,printf需要指定fotmat; 2.format用于指定后面的每个item的输出格式; 3.printf语句不会自动打印换行符:\\n format格式的指示符都以%开头,后跟一个字符;如下: % c:显示字符的ASCII码; % d,%i:十进制整数; % e,%E:科学计数法显示数值; % f:显示浮点数; % g,%G:以科学计数法的格式或浮点数的格式显示数值; % s:显示字符串 % u:无符号整数 % %:显示%自身 printf修饰符: -:左对齐,默认右对齐; +:显示数值符号:printf"%+d"
printf动作默认不会添加换行符
print默认添加空格换行符
1 2 3 4 5 6 [root@RockyLinux awk]# awk '{printf $0}' awktest3 test1 test2 test3 test4test5 test6 test7 test8test9 test10 [root@RockyLinux awk]# awk '{print $0}' awktest3 test1 test2 test3 test4 test5 test6 test7 test8 test9 test10
给printf添加格式
1 2 3 4 [root@RockyLinux awk]# awk '{printf "%s\n",$1}' awktest3 test1 test5 test9
对多个变量进行格式化 当我们使用Linux命令printf时,一个%s格式替换符,可以对多个参数进行重复格式化
1 2 [root@RockyLinux awk]# printf "%s\n" a,b,c,d,e a,b,c,d,e
然而awk的格式化替换符想要改变多个变量,必须传入多个
1 2 3 4 5 [root@RockyLinux awk]# awk 'BEGIN{printf "%d\n%d\n%d\n%d\n",1,2,3,4}' 1 2 3 4
printf对输出的文本不会换行,必须添加对应的格式替换符和\n
使用printf动作,'{print "%s\n",$1}',替换的格式和变量之间得有逗号
使用printf动作,%s %d等格式化替换符必须要和被格式化的数据一一对应
printf案例 1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk -F ":" '{printf "第1列:%s 第2列:%s 第3列:%s 第4列:%s 第5列:%s\n",$1,$2,$3,$4,$5}' awktest1 第1列:qhuai1 第2列:qhuai2 第3列:qhuai3 第4列:qhuai4 第5列:qhuai5 第1列:qhuai6 第2列:qhuai7 第3列:qhuai8 第4列:qhuai9 第5列:qhuai10 第1列:qhuai11 第2列:qhuai12 第3列:qhuai13 第4列:qhuai14 第5列:qhuai15 第1列:qhuai16 第2列:qhuai17 第3列:qhuai18 第4列:qhuai19 第5列:qhuai20 第1列:qhuai21 第2列:qhuai22 第3列:qhuai23 第4列:qhuai24 第5列:qhuai25 第1列:qhuai26 第2列:qhuai27 第3列:qhuai28 第4列:qhuai29 第5列:qhuai30 第1列:qhuai31 第2列:qhuai32 第3列:qhuai33 第4列:qhuai34 第5列:qhuai35 第1列:qhuai36 第2列:qhuai37 第3列:qhuai38 第4列:qhuai39 第5列:qhuai40 第1列:qhuai41 第2列:qhuai42 第3列:qhuai43 第4列:qhuai44 第5列:qhuai45 第1列:qhuai46 第2列:qhuai47 第3列:qhuai48 第4列:qhuai49 第5列:qhuai50
awk通过空格切割文档
printf动作对数据格式化
对passwd文件格式化输出 1 2 3 4 5 6 7 8 9 10 数据准备 [root@RockyLinux awk]# cat /etc/passwd >> /root/linuxtest/awk/passwd 格式化输出 [root@RockyLinux awk]# awk -F ":" 'BEGIN{printf "%-20s\t%-10s\t%-10s\t%-10s\t%-40s\t%-25s\t%-25s\n","用户名","密码","UID","GID","用户注释","用户家目录","用户解释器"} {printf "%-20s\t%-10s\t%-10s\t%-10s\t%-40s\t%-25s\t%-25s\n",$1,$2,$3,$4,$5,$6,$7}' passwd 参数说明: % s是格式替换符,替换字符串 % s\t格式化字符串后,添加制表符,四个空格 % -25s已然是格式化字符串,-代表左对齐,25个字符长度
awk案例 准备测试内容
1 [root@RockyLinux awk]# cat /etc/passwd > passwd.txt
显示文件第5行 1 2 3 4 5 6 7 NR在awk中表示行号,NR==5 表示行号是5的那一行 注意一个等于号是修改变量值的意思,两个等于号是关系运算符,是等于的意思 [root@RockyLinux awk]# awk 'NR==5' passwd.txt lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@RockyLinux awk]# grep -n ".*" passwd.txt | awk 'NR==5' 5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
显示文件2-5行 设置模式(条件)
1 2 3 4 5 6 7 8 9 10 11 12 告诉awk,我要看行号2到5的内容 [root@RockyLinux awk]# awk 'NR==2,NR==5' passwd.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@RockyLinux awk]# grep -n ".*" passwd.txt | awk 'NR==2,NR==5' 2:bin:x:1:1:bin:/bin:/sbin/nologin 3:daemon:x:2:2:daemon:/sbin:/sbin/nologin 4:adm:x:3:4:adm:/var/adm:/sbin/nologin 5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
给每一行的内容添加行号 添加变量,NR等于行号,$0表示一整行的内容
{print}是awk的动作
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk '{print NR,$0}' awktest1 1 qhuai1 qhuai2 qhuai3 qhuai4 qhuai5 2 qhuai6 qhuai7 qhuai8 qhuai9 qhuai10 3 qhuai11 qhuai12 qhuai13 qhuai14 qhuai15 4 qhuai16 qhuai17 qhuai18 qhuai19 qhuai20 5 qhuai21 qhuai22 qhuai23 qhuai24 qhuai25 6 qhuai26 qhuai27 qhuai28 qhuai29 qhuai30 7 qhuai31 qhuai32 qhuai33 qhuai34 qhuai35 8 qhuai36 qhuai37 qhuai38 qhuai39 qhuai40 9 qhuai41 qhuai42 qhuai43 qhuai44 qhuai45 10 qhuai46 qhuai47 qhuai48 qhuai49 qhuai50
显示5-9行的信息并输出行号 1 2 3 4 5 6 [root@RockyLinux awk]# awk 'NR==5,NR==9{print NR,$0}' passwd.txt 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
显示第1列,倒数第2列和倒数第3列 1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux awk]# awk '{print $1,$(NF-1),$(NF-2)}' awktest1 qhuai1 qhuai4 qhuai3 qhuai6 qhuai9 qhuai8 qhuai11 qhuai14 qhuai13 qhuai16 qhuai19 qhuai18 qhuai21 qhuai24 qhuai23 qhuai26 qhuai29 qhuai28 qhuai31 qhuai34 qhuai33 qhuai36 qhuai39 qhuai38 qhuai41 qhuai44 qhuai43 qhuai46 qhuai49 qhuai48
awk取IP地址 1 2 [root@RockyLinux awk]# ifconfig ens2 | awk 'NR==2{print $2}' 192.168.100.100
awk模式pattern 回顾awk的语法:
1 awk [option] 'pattern[action]' file...
awk是按行处理文本,上文讲解了print动作,现在讲解特殊的pattern:BEGIN和END
1 2 3 4 5 6 7 8 [root@RockyLinux awk]# awk 'BEGIN{print "这是处理文本之前需要执行的操作"}' awktest3 这是处理文本之前需要执行的操作 [root@RockyLinux awk]# awk 'BEGIN{print "这是处理文本之前需要执行的操作"} {print $0}' awktest3 这是处理文本之前需要执行的操作 test1 test2 test3 test4 test5 test6 test7 test8 test9 test10
可以看出,若只设置BEGIN操作进行输出,不会将文件内容进行输出,只有再添加一个动作比如打印每行的操作后才会输出文本内容。
1 2 3 4 5 6 7 8 [root@RockyLinux awk]# awk 'END{print "这是文本处理之后执行的操作"}' awktest3 这是文本处理之后执行的操作 [root@RockyLinux awk]# awk 'END{print "这是文本处理之后执行的操作"} {print $0}' awktest3 test1 test2 test3 test4 test5 test6 test7 test8 test9 test10 这是文本处理之后执行的操作
可以看出,若只设置END操作进行输出,不会将文件内容进行输出,只有再添加一个动作比如打印每行的操作后才会输出文本内容,并且END会在处理完文本之后再执行操作。
模式pattern讲解 1 2 语法: awk [option] 'pattern[action]' file...
awk语法当中,模式也可以理解为条件。
而上文种的BEGIN和END就是两个条件(pattern)。
awk默认是按行处理文本,如果不指定任何模式(条件),awk默认一行行处理。
如果指定了模式,只有符合模式的才会被处理。
awk模式
关系运算符
解释
示例
<
小于
x < y
<=
小于等于
x <= y
==
等于
x == y
!=
不等于
x != y
>=
大于等于
x >= y
>
大于
x > y
~
匹配正则
x~/正则/
!~
不匹配正则
x !~ /正则/
eg:
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@RockyLinux awk]# awk 'NR==3,NR==7 {print $0}' awktest1 qhuai11:qhuai12:qhuai13:qhuai14:qhuai15 qhuai16:qhuai17:qhuai18:qhuai19:qhuai20 qhuai21:qhuai22:qhuai23:qhuai24:qhuai25 qhuai26:qhuai27:qhuai28:qhuai29:qhuai30 qhuai31:qhuai32:qhuai33:qhuai34:qhuai35 [root@RockyLinux awk]# grep -n ".*" awktest1 | awk 'NR==3,NR==7 {print $0}' 3:qhuai11:qhuai12:qhuai13:qhuai14:qhuai15 4:qhuai16:qhuai17:qhuai18:qhuai19:qhuai20 5:qhuai21:qhuai22:qhuai23:qhuai24:qhuai25 6:qhuai26:qhuai27:qhuai28:qhuai29:qhuai30 7:qhuai31:qhuai32:qhuai33:qhuai34:qhuai35
awk与正则表达式 正则表达式主要与awk的pattern(条件)结合使用
不指定模式,awk每一行都会执行对应的动作
制定了模式,只有被模式匹配到的、符合条件的行才会执行动作
awk正则语法 1 2 awk '/正则表达式/{动作}' 文件 awk '/正则表达式1/,/正则表达式2/{动作}' 文件 #找出区间的内容
awk命令使用正则表达式,必须把正则放入”//“双斜杠中,匹配到结果后执行动作{print $0},打印整行信息。
awk强大的格式化文本 1 2 3 [root@RockyLinux awk]# awk -F ":" 'BEGIN{printf "%-10s\t%-10s\n","用户名","用户id"} /^n/{printf "%-10s\t%-10s\n",$1,$3}' passwd 用户名 用户id nobody 65534
找出passwd种有以games开头的行
1.使用grep过滤
1 2 [root@RockyLinux awk]# grep -n "^games" passwd 11:games:x:12:100:games:/usr/games:/sbin/nologin
2.awk查找
1 2 [root@RockyLinux awk]# awk '/^games/{print $0}' passwd games:x:12:100:games:/usr/games:/sbin/nologin
awk命令执行流程 解读需求:从passwd文件中,寻找我们想要的信息,按照以下顺序执行
1 awk 'BEGIN{commands} pattern{commands} END{commands}'
1.优先执行BEGIN{}模式中的语句
2.从passwd文件中读取第一行,然后执行pattern{commands}进行正则匹配/^n/寻找n开头的行,找到了执行{print}打印
3.当awk读取到文件数据流的结尾时,会执行END{commands}
eg:
找出passwd文件中禁止登陆的用户(/sbin/nologin)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 找出passwd文件中禁止登陆的用户(/sbin/nologin) 正则表达式中如果出现了"/"则需要进行转义 1.使用grep方法 [root@RockyLinux awk]# grep -n "/sbin/nologin$" passwd 2:bin:x:1:1:bin:/bin:/sbin/nologin 3:daemon:x:2:2:daemon:/sbin:/sbin/nologin 4:adm:x:3:4:adm:/var/adm:/sbin/nologin 5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 9:mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10:operator:x:11:0:operator:/root:/sbin/nologin 11:games:x:12:100:games:/usr/games:/sbin/nologin 2.使用awk找出 [root@RockyLinux awk]# awk '/\/sbin\/nologin$/{print NR,$0}' passwd 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin 11 games:x:12:100:games:/usr/games:/sbin/nologin
找出文件的区间内容
1 2 3 4 5 6 7 [root@RockyLinux awk]# awk '/^operator/,/dbus/{print NR,$0}' passwd 10 operator:x:11:0:operator:/root:/sbin/nologin 11 games:x:12:100:games:/usr/games:/sbin/nologin 12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin 13 nobody:x:65534:65534:Kernel Overflow User:/:/sbin/nologin 14 systemd-coredump:x:999:999:systemd Core Dumper:/:/sbin/nologin 15 dbus:x:81:81:System message bus:/:/sbin/nologin
awk企业级实战 awk企业实战之nginx日志 统计日志的访客ip数量
1 2 3 4 5 sort -n 数字从大到小排序 wc -l 统计行数及IP的条目数 uniq 去重 [root@RockyLinux awk]# awk '{print $1}' access.log | sort -t "." -n -k1,1n -k2,2n -k3,3n -k4,4n | uniq | wc -l 191
查看访问最频繁的前10个ip
1 2 3 4 5 6 7 8 9 10 11 12 13 14 uniq -c 去重显示次数 sort -nr 从大到小排序 [root@RockyLinux awk]# awk '{print $1}' access.log | sort -t "." -n -k1,1n -k2,2n -k3,3n -k4,4n | uniq -c | sort -nr | head -10 59 183.241.20.44 46 89.117.48.162 19 217.114.43.119 12 91.224.92.17 12 35.182.219.207 12 18.61.29.13 11 137.184.116.225 10 171.219.236.159 8 98.130.120.187 8 35.182.17.24
三剑客练习题 grep练习题 找出/etc/passwd中有关root的行
1 2 3 [root@RockyLinux grep]# grep -n "root" /etc/passwd 1:root:x:0:0:root:/root:/bin/bash 10:operator:x:11:0:operator:/root:/sbin/nologin
找出/etc/passwd中root开头的行
1 2 [root@RockyLinux grep]# grep -n "^root" /etc/passwd 1:root:x:0:0:root:/root:/bin/bash
匹配/etc/passwd中以root开头或者以nginx开头的行
1 2 3 4 精准匹配需要加上">"符号 [root@RockyLinux grep]# grep -E -n "^(root|nginx)\>" /etc/passwd 1:root:x:0:0:root:/root:/bin/bash 34:nginx:x:986:985:Nginx web server:/var/lib/nginx:/sbin/nologin
过滤出/etc/passwd中以bin开头的行
1 2 [root@RockyLinux grep]# grep -n "^bin" /etc/passwd 2:bin:x:1:1:bin:/bin:/sbin/nologin
过滤出除了root开头的行
1 2 3 4 5 [root@RockyLinux grep]# grep -nv "^root" /etc/passwd 2:bin:x:1:1:bin:/bin:/sbin/nologin 3:daemon:x:2:2:daemon:/sbin:/sbin/nologin 4:adm:x:3:4:adm:/var/adm:/sbin/nologin 5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
统计qinhuai用户出现的次数
1 2 [root@RockyLinux grep]# grep -c "^qinhuai" /etc/passwd 3
匹配qinhuai用户,最多两次
1 2 3 [root@RockyLinux grep]# grep -m 2 "^qinhuai" /etc/passwd qinhuai1:x:1000:1000::/home/qinhuai1:/bin/bash qinhuai2:x:1001:1001::/home/qinhuai2:/bin/bash
匹配多文件,列出存在信息的文件名字
1 2 [root@RockyLinux grep]# grep -l "qinhuai" /etc/passwd passwd.txt /etc/passwd
显示/etc/passwd文件中不以/bin/bash结尾的行
1 2 3 4 5 6 [root@RockyLinux grep]# grep -nv "/bin/bash$" /etc/passwd 2:bin:x:1:1:bin:/bin:/sbin/nologin 3:daemon:x:2:2:daemon:/sbin:/sbin/nologin 4:adm:x:3:4:adm:/var/adm:/sbin/nologin 5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6:sync:x:5:0:sync:/sbin:/bin/sync
找出/etc/passwd文件中的两位数或三位数
1 2 需要"< >"使用到精准匹配 [root@RockyLinux grep]# grep -E -n "\<[0-9]{2,3}\>" /etc/passwd
找出文件中,以至少一个空白字符开头,后面是非空字符的行
1 [root@RockyLinux grep]# grep "^[[:space:]].*" lovers.txt
找出lovers.txt文件中,所有大小写i开头的行
1 2 3 4 5 6 [root@RockyLinux grep]# grep -i "^i" lovers.txt I love my lover. [root@RockyLinux grep]# grep -E "^(i|I)" lovers.txt I love my lover. [root@RockyLinux grep]# grep -E "^[iI]" lovers.txt I love my lover.
找出系统上root、qinhuai、nobody用户的信息
注意,系统中可能存在多个近似用户,精确搜索得加上<>
1 2 3 4 [root@RockyLinux grep]# grep -E "^(root|qinhuai|nobody)\>" /etc/passwd root:x:0:0:root:/root:/bin/bash nobody:x:65534:65534:Kernel Overflow User:/:/sbin/nologin qinhuai:x:1003:1003::/home/qinhuai:/bin/bash
找出/usr/lib/tuned/functions文件中的所有函数名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@RockyLinux tuned]# grep -o -E "[a-zA-Z]+\()" /usr/lib/tuned/functions value() sys() sys() sys() sys() sys() value() sys() override() [root@RockyLinux tuned]# grep -E -o "[[:alnum:]]+\()" /usr/lib/tuned/functions value() sys() sys() sys() sys() sys() value() sys() override()
找出用户名和shell相同的用户
1 2 3 4 [root@RockyLinux tuned]# grep -E "^([^:]+\>).*\1$" /etc/passwd sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt
sed练习题 提示:sed命令加上-i参数后将结果写入到文件
替换文件的root为qinhuai,替换一次与替换所有
1 2 3 4 5 6 7 [root@RockyLinux sed]# sed -n 's/root/qinhuai/p' passwd qinhuai:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/qinhuai:/sbin/nologin [root@RockyLinux sed]# sed -n 's/root/qinhuai/gp' passwd qinhuai:x:0:0:qinhuai:/qinhuai:/bin/bash operator:x:11:0:operator:/qinhuai:/sbin/nologin
替换前10行b开头的用户,改为c,且仅仅显示替换的结果
1 2 [root@RockyLinux sed]# sed -n '1,10s/^bin/C/p' passwd C:x:1:1:bin:/bin:/sbin/nologin
替换前10行b开头的用户,改为C,且将m开头的行,改为M且仅仅显示替换的结果
1 2 3 [root@RockyLinux sed]# sed -n -e '1,10s/^bin/C/p' -e 's/^m/M/p' passwd C:x:1:1:bin:/bin:/sbin/nologin Mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
删除4行后面所有
1 2 3 4 5 [root@RockyLinux sed]# sed '5,$d' passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin
删除从root开始,到ftp之间的行
1 [root@RockyLinux sed]# sed '/^root/,/^ftp/d' passwd
把文件空白字符开头的行,添加注释符
实验内容
1 2 3 4 5 6 [root@RockyLinux sed]# cat -n lovers 1 I like my lover. 2 I love my lover. 3 He likes his lovers. 4 He love his lovers. 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@RockyLinux sed]# sed -e 's/^[[:space:]]/#/g' -e 's/^$/#/g' lovers # I like my lover. I love my lover. # He likes his lovers. He love his lovers. # 使用正则扩展的(|) [root@RockyLinux sed]# sed -r 's/(^[[:space:]]|^$)/#/g' lovers # I like my lover. I love my lover. # He likes his lovers. He love his lovers. #
删除文件的空白和注释行
实验内容
1 2 3 4 5 6 7 8 9 [root@RockyLinux sed]# cat -n lovers 1 I like my lover. 2 I love my lover. 3 He likes his lovers. 4 He love his lovers. 5 6 # 7 8 #
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@RockyLinux sed]# sed -e '/^$/d' -e '/^#/d' lovers I like my lover. I love my lover. He likes his lovers. He love his lovers. 使用正则扩展 [root@RockyLinux sed]# sed -r '/^($|#)/d' lovers I like my lover. I love my lover. He likes his lovers. He love his lovers. 使用";"多次执行 [root@RockyLinux sed]# sed '/^$/d;/^#/d' lovers I like my lover. I love my lover. He likes his lovers. He love his lovers.
给前三行添加@符号
1 2 3 4 5 6 7 8 9 [root@RockyLinux sed]# sed -r '1,3s/(^.)/@\1/' lovers @ I like my lover. @I love my lover. @ He likes his lovers. He love his lovers. # #
取出ip地址
1 2 3 4 5 6 7 8 9 10 11 1.去头去尾 [root@RockyLinux sed]# ifconfig ens2 | sed -n '2p' | sed 's/^.*inet //' | sed 's/ netmask.*$//' 192.168.100.100 2.-e参数进行多次编辑 [root@RockyLinux sed]# ifconfig ens2 | sed -n -e '2s/^.*inet //' -e '2s/ netm.*$//p' 192.168.100.100 3.使用";"多次编辑 [root@RockyLinux sed]# ifconfig ens2 | sed '2s/^.*inet //;2s/ netm.*$//p' -n 192.168.100.100
找出系统版本
1 2 [root@RockyLinux sed]# grep -i -E "^PRETTY_NAME" /etc/os-release | sed -n 's/^.*="//;s/".*$//p' Rocky Linux 9.6 (Blue Onyx)
awk练习题 在当前系统中打印出所有普通的用户和家目录(passwd)
1 2 3 4 5 [root@RockyLinux awk]# awk -F ":" '$3>1000{print $1,$(NF-1)}' passwd nobody / qinhuai2 /home/qinhuai2 qinhuai3 /home/qinhuai3 qinhuai /home/qinhuai
给awktest1前五行添加#号
1 2 3 4 5 6 [root@RockyLinux awk]# awk -F ":" 'NR<6{print "#",$0}' awktest1 # qhuai1:qhuai2:qhuai3:qhuai4:qhuai5 # qhuai6:qhuai7:qhuai8:qhuai9:qhuai10 # qhuai11:qhuai12:qhuai13:qhuai14:qhuai15 # qhuai16:qhuai17:qhuai18:qhuai19:qhuai20 # qhuai21:qhuai22:qhuai23:qhuai24:qhuai25
以多个字符为分隔符并删除空白行
1 awk -F "[ :]" '!/^$/{print $0}' filename
对具体的列进行正则匹配
1 awk -F "[ :]" '$n~/正则条件/{print $n}' filename
Linux定时任务 Cron是Linux系统中以后台进程模式周期性执行命令或指定程序任务的服务软件名。
Linux系统启动后,cron软件便会启动,对应的进程名字叫做crond,默认是定期(每分钟检查一次)检查系统中是或否有需要执行的任务计划,如果有则按计划进行。
crond定时任务默认最快的频率是每分钟执行。
若是需要以秒为单位的计划执行任务,则编写shell脚本更合适,crond不适用。
atat定时任务工具,依赖atd服务,适用于执行一次就结束的调度任务,例如突发任务,某天夜里3点需要临时性备份数据,可以使用at软件。
1 2 3 4 5 6 7 8 9 10 HH:MM YYYY-mm-dd moon 正午12点 midnight 午夜12点 teatime 下午茶时间,下午4点 tomorrow 明天 now+1min 一分钟之后 now+1minutes/hours/days/weeks
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 用法: 假如我要在1分钟后执行 mkdir -p /root/linuxtest/at 先在终端输入 at now+1min 输入之后就会进入命令输入框,输入要执行的命令 at> mkdir -p /root/linuxtest/at输入完成后按下Ctrl + dt提交命令任务 运行之后可以通过mail命令检查at的执行结果 [root@RockyLinux ~]# at now+1min warning: commands will be executed using /bin/sh at> mkdir -p /root/linuxtest/atat> <EOT> job 1 at Sat Sep 13 15:19:00 2025 [root@RockyLinux ~]# ls /root/linuxtest/ at awk grep sed 检查定时任务 at -l 列出等待中的作业 通过文件交互式读取任务,不用交互式输入 cat test.at echo "这是at定时执行的文件" at -f ./test.at now+3min 删除任务 at -d 6 atrm 6 两条命令效果相同
cron向crond进程提交任务的方式与at不同,crond需要读取配置文件,且有固定的文件格式,通过crontab命令管理文件
cron任务分为两种:
系统定时任务 crond服务除了会在工作时查看/var/spool/cron文件下的定时任务文件以外,还会查看/etc/cron.d目录以及/etc/anacrontab下面的文件内容,里面存放每天、每周、每月 需要执行的系统任务
1 2 3 4 5 6 7 8 9 10 [root@RockyLinux postfix]# ls -l /etc/ | grep cron* -rw-r--r--. 1 root root 541 May 2 17:15 anacrontab drwxr-xr-x. 2 root root 21 Jul 13 11:04 cron.d #系统定时任务 drwxr-xr-x. 2 root root 6 May 11 2022 cron.daily #每天执行的定时任务 -rw-r--r--. 1 root root 0 May 2 17:15 cron.deny drwxr-xr-x. 2 root root 22 May 11 2022 cron.hourly #每小时执行的定时任务 drwxr-xr-x. 2 root root 6 May 11 2022 cron.monthly #每月的定时任务 drwxr-xr-x. 2 root root 6 May 11 2022 cron.weekly #每周的定时任务 -rw-r--r--. 1 root root 451 May 11 2022 crontab drwxr-xr-x. 3 root root 32 Jul 13 11:06 microcode_ctl
系统定时任务配置文件/etc/crontab 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@RockyLinux postfix]# cat /etc/crontab SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin #路径信息很少,因此定时任务用绝对路径 MAILTO=root #执行结果发送邮件给用户 # For details see man 4 crontabs # Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user-name command to be executed 每一行就是一条周期性任务 user-name 是以某一个用户身份运行任务 command to be executed 任务是什么
用户定时计划任务 当系统管理员或是普通用户用户创建了需要定期执行的任务,可以使用crontab命令配置,crond用户在启动时,会每分钟查看/var/spool/cron路径下以系统用户名命名的定时任务文件,以确定是否有需要执行的任务。
1 2 [root@RockyLinux postfix]# crontab -l no crontab for root
crontab命令 crontab命令被用来提交和管理用户的需要周期性执行的任务,与Windows的计划任务类似。
参数
解释
使用示例
-l
list查看定时任务
crontab -l
-e
edit编辑定时任务,建议手动编辑
crontab -e
-i
删除定时任务,提示用户确认删除,避免出错
crontab -i
-r
删除定时任务,移除/var/spool/cron/username文件,会被全部删除
crontab -r
-u user
指定用户执行任务,root可以管理普通用户计划任务
crontab -u qinhuai -l
crontab命令就是在修改/var/spool/cron中的定时任务文件。
时间表示
特定值,时间点有效取值范围内的值
通配符,某时间点有效范围内的所有值,表示”每”的意思
特殊符号
含义
*
表示“每”的意思,如00 23 * * * cmd表示每月每周每日的23:00执行命令
-
表示时间范围分隔符,如0 17-19 * * * cmd,代表每天的17、18、19点执行命令
,
表示分隔时段,如30 17,19,21 * * cmd表示每天的17,19,21点半执行命令
/n
n表示可以整除的数字,每隔n的单位时间,如每隔10分钟表示*/10 * * * * cmd
1 2 3 4 5 6 7 8 9 10 0 * * * * 每小时执行,每小时的整点执行 1 2 * * 4 每周四的凌晨2点1分执行 1 2 3 * * 每月3号的凌晨2点1分执行 1 2 3 4 * 每年的4月3号凌晨2点1分执行 1 2 * * 3,5 每周3,周5的凌晨2点1分执行 * 13,14 * * 6,0 每周六周日的下午1点和2点的每一分钟执行 0 9-18 * * 1-5 每周1到周五的9点到18点整点执行 */10 * * * * 每隔10分钟执行一次任务 *7 * * * * 如果没法整除,定时任务则没有意义,可以自定制脚本控制频率 定时任务最小单位是分钟,如果想完成秒级任务,只能通过其他方式(编程语言)来实现
Linux磁盘管理与文件系统 磁盘存储单位解释 **扇区secttor**:是磁盘中最小的物理存储单元,单位 512字节 512Bytes
**块block*:操作系统无法对数目众多的扇区进行寻址,因此操作系统将相邻的扇区组合在了一起,形成了块block(8个扇区,8 512Bytes 4kb大小)。在Linux文件系统中多个连续的扇区被称之为block,块的概念,也是在系统中被认为是最小的存储单位。操作系统规定,一个block只能存放一个文件的内容,因此文件占用的空间大小只能是block的整数倍。即使文件大小,小于一个块,也就是小于4k,同样的占用一个block大小。
**簇**:在Windows文件系统中,多个连续的扇区被称之为簇。
**分区编辑器**:fdisk,对磁盘进行格式化的命令,以及分区等等。
**MBR分区表**:master boot record,主分区引导记录。mbr占446字节,分区表占64字节,结束标志占2字节。MBR分区关注的是硬盘容量受限制,最大2T。
**GPT分区表**:现在大多的硬盘分区表,都是GPT分区表。其优点是硬盘容量没有限制,分区个数没有限制,自带磁盘保护机制。
常见文件系统 **FAT16 or FAT32**:最早的Windows文件系统,缺点是单个文件不能超过2GB
**NTFS**:支持文件加密,采用日志形式的文件系统,详细的记录磁盘读写的操作,支持数据恢复,能够提高磁盘数据的安全性,突破了单个文件4G大小的限制
**exFAT**:新式的文件系统,单个文件支持16GB大小,能够在Windows和Linux,MacOS中同时识别。
fidsk分区 Linux中一切皆文件,磁盘设备在系统中也以文件形式展示
装置
装置在Linux内的文件名
IDE硬盘机
/dev/hd[a-d]
SCSI/SATA/USB硬盘机
/dev/sd[a-p]
USB快闪碟
/dev/sd[a-p](与SATA不同)
软盘驱动器
/dev/fd[0-1]
打印机
25针:/dev/lp[0-2]
鼠标
PS2:/dev/psaux
当前CDROM/DVDROM
/dev/cdrom
当前的鼠标
/dev/mouse
系统默认分区1~4留给了主分区和扩展分区
主分区1*(星号代表了是引导分区,引导分区装在这里)
主分区2
主分区3
主分区4(extended)
逻辑分区n
对于磁盘容量在2TB以下的可以使用fdisk命令进行分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 查看分区表 fdisk -l 对某个磁盘进行分区,如sdb磁盘 fdisk /dev/sdb 进入磁盘分区后有几个常用参数 输入m进入帮助命令 输入n进入添加分区 输入p创建主分区 输入e创建拓展分区 扩展分区可以创建逻辑分区输入l即可创建 输入d对分区进行删除 输入q不对分区情况进行保存直接退出 输入w对分区情况进行保存后退出 输入p打印分区表
fdisk命令创建好分区后还需要告诉内核重新加载分区表
parted分区 小于2TB的磁盘都可以使用fdisk命令进行分区,但是大于2TB的磁盘,只能用parted命令分区,且转换磁盘为GPT格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 parted -l 显示所有分区信息 进入parted分区,GPT分区表没有extend类型 [root@RockyLinux ~]# parted /dev/sdb GNU Parted 3.5 Using /dev/sdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) mklabel gpt #将磁盘格式改为GPT格式 (parted) p Model: QEMU QEMU HARDDISK (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags (parted) mkpart primary 0 500 #创建主分区设置大小为500M Warning: The resulting partition is not properly aligned for best performance: 34s % 2048s != 0s Ignore/Cancel? Ignore (parted) mkpart logical 501 1501 #创建逻辑分区设置大小1GB (parted) p Model: QEMU QEMU HARDDISK (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 17.4kB 500MB 500MB primary 2 501MB 1501MB 999MB logical (parted) q #退出pated并保存分区情况 Information: You may need to update /etc/fstab. [root@RockyLinux ~]# fdisk -l | grep sdb Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors /dev/sdb1 34 976562 976529 476.8M Linux filesystem /dev/sdb2 978944 2930687 1951744 953M Linux filesystem
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 命令参数 [root@RockyLinux ~]# parted /dev/sdb GNU Parted 3.5 Using /dev/sdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) help align-check TYPE N 检查分区 N 以获取 TYPE(min|opt) 对齐 help [COMMAND] 打印一般帮助,或对命令的帮助 mklabel,mktable LABEL-TYPE 创建一个新的磁盘标签(分区表) mkpart PART-TYPE [FS-TYPE] START END 制作一个分区 name NUMBER NAME 将分区号命名为名称 print [devices|free|list,all] 显示分区表,或者可用设备,或者空闲空间,或者找到的所有分区 quit 退出程序 rescue START END 在起始和结束附近恢复一个丢失的分区 resizepart NUMBER END 调整分区大小 NUMBER rm NUMBER 删除分区 NUMBER select DEVICE 选择要编辑的设备 disk_set FLAG STATE 更改选定设备上的标志 disk_toggle [FLAG] 切换选定设备上 FLAG 的状态 set NUMBER FLAG STATE 更改分区号码上的标志 toggle [NUMBER [FLAG]] 切换分区NUMBER上FLAG的状态 type NUMBER TYPE-ID or TYPE-UUID 输入分区编号的类型ID或类型UUID unit UNIT 将默认单位设置为单位 version 显示GNU Parted的版本号和版权信息
文件系统格式化 文件系统介绍
ext2
ext3 centos5
ext4 centos6
xfs centos7
nfs network file system
smb server message block 服务消息块
gfs Google file system 是Google公司为了存储海量的数据而开发的文件系统
ocfs Oracle cluster file system 是Oracle公司为了数据库研发平台而定制的文件系统
ceph 为了存储的可靠性和扩展性的分布式文件系统
swap
文件系统创建工具 创建文件系统
1 2 3 4 5 6 7 8 9 10 mkfs命令 mkfs把分区格式化为某种文件系统 mkfs.文件系统类型 磁盘 eg: mkfs.ext4 /dev/sdb1 root@qinhuai:~# mkfs mkfs mkfs.bfs mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.fat mkfs.minix mkfs.msdos mkfs.ntfs mkfs.vfat mkfs.xfs
修复文件系统
1 2 3 4 5 fsck fsck -t xfs /dev/sd[] 检查并修复Linux文件系统,默认读取/etc/fstab开机挂载文件 禁止系统开机修复错误 修改/etc/fstab文件,将末尾的数字改为0
列出所有的设备以及文件系统信息
设置Linux是否开机自动检查文件系统正常与否
1 2 3 tune2fs 关闭文件系统自检 tune2fs -c -1 /dev/sd[][0-9]
文件系统挂载 mount命令能够将指定多个文件系统挂载到指定的目录上(挂载点,Linux系统上的一个文件夹)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 mount命令常用参数 -l 显示系统所有挂载的设备信息 -t 指定设备的文件系统类型,如果不指定,mount自动选择挂载的文件系统类型 -o 添加挂载的功能选项,用的很多 -r read,挂载后的设备是只读的 -w 读写参数,相当于-o rw权限,云南徐挂在后读写操作 mount -o 参数详解 async 以异步的方式处理文件系统IO加速写入,数据不会同步的写入到磁盘,写入到一个缓冲区,提高系统性能,损失数据安全性 sync 所有的IO操作同步处理,数据同步写入到磁盘,性能较弱但是能够提高系统数安全性。 atime/noatime 文件被访问的时候,是否修改其时间戳,不修改其时间戳能够提升磁盘IO速度 auto/noauto 可以通过-a参数自动挂载,不自动挂载 defaults 这个默认参数涵盖了rw,suid,dev,exec,auto,nouser,async等参数 exec/noexec 是否允许执行挂载点内的可执行命令,使用了noexec提升磁盘安全性 ro 只读 rw 读写 att2 在磁盘上存储内连扩展属性,提升磁盘性能 inode64 允许在文件系统的任意位置创建inode noquta 强制关闭文件系统的限额功能
案例 1 2 3 4 5 6 7 8 1.对/dev/sdb2分区进行格式化 mkfs .xfs /dev/sdb2 2.挂载/dev/sdb2到/mnt/sdb2目录下然后写入数据 mkdir -p /mnt/sdb2 mount /dev/sdb2 /mnt/sdb2 3.进入/mnt/sdb2目录写入数据 4.取消挂载/dev/sdb2(确保此时/mnt/sdb2目录里没有任何写入和读取操作) umount /mnt/sdb2
swap交换分区 swap分区时Linux系统磁盘管理的一块特殊的分区,当实际的物理内存不足的时候,操作系统会从整个磁盘中取出一部分暂时没在使用的存储,拿出来放到交换分区,从而提供给当前正在使用的程序,可以使用更多的内容。
使用swap分区作用是,通过操作系统的调取,程序可以用到的实际内存会远大于物理内存。
swap分区大小必须根据物理内存和硬盘容量来计算。
当物理内存小于1G,必须使用swap提升内存使用量。
当内存使用过多的应用程序,比如图像、视频等,必须用swap分区防止物理内存不足,造成软件崩溃。
当电脑处于休眠时,内存中的数据会放入swap交换分区中,当电脑恢复后再从swap中读取数据,恢复软件正常工作。
swap分区创建规则计算如下:
内存小于2G时,swap分配和内存同样大小的空间。
内存大于2G时,swap也就分配2G的空间。
创建swap分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1.先给磁盘分一个区并指定swap分区类型 fdisk /dev/sd[] 输入n 再输入p创建一个主分区 分配+1G 再输入t 并输入82代码,此代码为swap分区的代码 2.针对磁盘分区进行格式化 mkswap /dev/sd[] 3.再来使用swap分区 开启swap分区 swapon 关闭swap分区 swapoff
buff和cache buffers:缓冲区,buffers是给写入数据加速使用的
cached:缓存,用于读取数据时,加速使用的
cached表示把数据从磁盘上读取出来,保存在内存中,再次读取的时候不再去硬盘上拉取数据,直接从内存中读取,加速查找
buffers表示在写入磁盘数据的时候把分散的操作临时保存在内存中,达到一定数量之后,集中写入到磁盘,减少磁盘碎片,加速数据查找,减少磁头的反复寻道时间。
buff和cache作用总结:
buffer和cached都是基于内存的存储中间层。cached解决时间问题,加速读取的过程。buffer解决空间存储问题,给数据一个临时存放的区域。cached利用内存的高速读写特性。buffer利用内存的存储空间特性。
假如内存占用与实际占用不匹配,通俗点来说就是内存被吃了,无故提示内存不足,但是cache,buff中又看到大量的内存如何释放。
1 2 3 4 5 6 7 8 9 10 1.释放cache命令 echo 1 > /proc/sys/vm/drop_caches 等同于 sysctl -w vm.drop_caches=1 2.清除目录缓存和inodes echo 2 > /proc/sys/vm/drop_caches 等同于 sysctl -w vm.drop_caches=2 3.清除内存页缓存 echo 3 > /proc/sys/vm/drop_caches 等同于 sysctl -w vm.drop_caches=3 以上三种都是临时释放缓存的命令 除了以上3个命令,还可以清理文件系统缓存,使用sync,可以用于清理僵尸进程(即主进程挂掉之后还保留的子进程) sync的作用:将内存缓冲区的数据,写入到磁盘中
开机自动挂载 由于mount命令挂载磁盘是临时性生效,下次重启的时候要使用该磁盘还需再次手动挂载,为了解决每次设备重启后再手动挂载的问题,我们需要在/etc/fstab文件中设置实现磁盘的开机自动挂载。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 /dev/sdb5 /mnt xfs default 0 0 第一列:是一个设备的名字,可以是文件系统,也可以是设备名称,NFS远程网络文件系统 mount /dev/sdb5 /mnt 是一种写法 mount 192.168.100.20:/nfs /mnt/ -o nolock 把本地的/mnt文件夹挂载到nfs文件系统上,且不加锁。 第二列:挂载点 就是自己在本机创建的一个目录,用于磁盘挂载的地方 第三列:Linux系统能够支持的文件系统类型 ext3 ext4 xfs nfs swap 第四列:挂载的功能选项,有很多,默认是用default 第五列:dump,表示将整个文件目录内容备份,一般部队挂载点备份,默认都是0 第六列:fsck 磁盘检查,默认是0不对磁盘检查,根文件系统,默认是检查的
磁盘容量统计 df命令,检查挂载点的使用情况
1 2 3 4 df命令的实际案例,可使用的参数如下: -h 显示kb mb大小 -i 显示已inode数量 -T 显示文件类型
du命令,显示磁盘空间大小,文件大小的命令
1 2 3 4 5 Linux文件存储最小单位是4K,也就是8个扇区 du -h 显示文件大小,以kb mb为单位 du -h * 显示当前目录所有文件的大小 du -a 显示出目录所有文件的大小
Raid raid全称为Redundant Arrays of Independent Drives,磁盘冗余阵列
raid技术时将多个独立的磁盘组成一个磁盘组,raid能够保证数据的安全性,但是也提高的了磁盘的成本。
raid技术意图在于把多个独立的硬盘设备,组成一个容量更大,安全性更高的磁盘阵列组,将数据切位多个区段之后分别存储在不同的物理硬盘上。利用分散读写技术提升磁盘整体性能,数据同步在了不同的多个磁盘上,数据也得到了冗余备份的作用。
standalone:独立模式,一块硬盘单独工作读写数据
hot swap:热备份模式,为了防止单独的一块硬盘损坏,随时准备好另一块硬盘准备接替工作
cluster:集群模式,一堆硬盘共同提供服务,提高读写效率,当一台机器坏了,可以切换到另一台机器继续业务运行
RAID0:特点是数据依次写入到物理硬盘中,在理想的状态下,写入速度是翻倍的。数据是写入到两块硬盘之中的,任意坏了一块硬盘,数据都将被破坏,没有备份功能。适用于追求极致性能的场景,而不关注于数据安全性的场景。
RAID1:由于raid0的特性,数据一次写入到多块硬盘中,数据是分开存储的,因此坏了任意一个,数据都将被破坏,对于企业非常重要的数据来说,肯定是不允许使用的。
而raid1是将两块以上的的硬盘绑定关系,数据写入的时候,同时写入到多块硬盘,因此即使磁盘故障损坏也不惧怕,但是降低了磁盘的利用率,假如使用两块硬盘一共4T大小,做了raid1后可使用的容量只有2T,利用率只有50%。
raid3:必须3块以上硬盘,磁盘1为0101,磁盘2为1011,异或结果为1110,如果磁盘1数据损坏,目前已知磁盘2和异或值即可反推磁盘1的数据,但是存储着异或值的磁盘不能损坏。
raid5:使用数据条带化(striping)的方式将数据分散存储在多个磁盘驱动器上,并通过分布式奇偶校验实现数据的冗余备份。数据和奇偶校验信息被组织成数据块,其中奇偶校验信息被分布式存储 在不同的驱动器上。当写入数据时,奇偶校验信息也会被更新。如果其中一个驱动器发生故障,系统可以通过重新计算奇偶校验信息来恢复丢失的数据。这种方式可以同时提供性能增强和数据冗余。
raid6:使用数据条带化(striping)的方式将数据分散存储在多个磁盘驱动器上,并通过分布式奇偶校验和双重奇偶校验实现数据的冗余备份。数据和奇偶校验信息被组织成数据块,其中奇偶校验信息被分布式存储在不同的驱动器上,并通过双重奇偶校验提供更高的数据冗余性。当写入数据时,奇偶校验信息也会被更新。如果其中两个驱动器发生故障,系统可以通过重新计算奇偶校验信息来恢复丢失的数据。这种方式可以同时提供性能增强和更高级别的数据冗余。
raid10:企业目前在用的是raid10版本,raid10是raid1加上raid0的意思。既吸收了raid0的特点,提升了数据的写入提高效率,又吸收了raid1的安全性因此至少需要4块硬盘完成。通过raid1技术实现了1磁盘两两备份,数据安全性较高。针对2个raid1的部署,又部署了raid0,提高了磁盘的读写效率。只要不是同一个硬盘组全部损坏,那么即使挂掉了一个硬盘也无所谓。
RAID级别
最小磁盘数
容错能力
磁盘空间开销
读取速度
写入速度
硬件成本
RAID 0
2
无
0%
高
高
低
RAID 1
2
单个磁盘
50%
高
低
中
RAID 5
3
单个磁盘
1/n
中
低
中
RAID 6
3
两个磁盘
2/n
中
低
高
RAID 10
4
多个磁盘
50%
高
中
高
RAID 50
6
单个磁盘
1/n
高
中
高
RAID 60
8
多个磁盘
50%
高
中
高
软RAID和硬RAID RAID常见的组合
raid0 raid1 raid5 raid10
软raid
一般通过操作系统或软件来实现,在软RAID中,数据冗余和条带化等功能完全由CPU和系统资源处理。
成本较低:软RAID不需要专门的硬件设备,因此成本较低。
灵活性较高:软RAID可以在不同的操作系统和平台上运行,具有较高的灵活性和兼容性,比如非加密的软RAID阵列,在其他操作系统下借助一定工具是可以读取数据的,这也是如果群晖阵列提示损坏后,恢复数据的一个比较稳妥的办法。
性能较低:由于软RAID依赖于CPU和系统资源,其性能可能受到限制,尤其是在高负载和I/O密集型任务下。
硬raid
硬RAID是通过专门的硬件设备(如RAID卡或阵列卡)实现RAID功能的方法。
成本较高:硬RAID需要专门的硬件设备,因此成本较高。
灵活性较低:硬RAID可能受限于特定的硬件设备和平台,兼容性和可移植性较低。
性能较高:由于硬RAID卸载了RAID功能的处理负担,它通常可以提供更高的性能和稳定性,尤其是在高负载和I/O密集型任务下。
数据冗余性能从好到坏:raid1 raid10 raid5 raid0
数据读写性能从好到坏:raid0 raid10 raid5 raid1
成本从高到低:raid0 raid1 raid5 raid10
应用场景 在不同的场景中,选择不同的raid磁盘阵列的级别。
单台服务器:数据很重要,但是磁盘不多,建议选择raid1。
数据库/存储服务器:建议选择raid10,如果采用主从架构,建议主服务器选择raid10,从服务器选择raid5来减少成本。
Web服务器:没有太多数据的话建议选择raid5或raid0。
有多台服务器:如监控服务器、应用服务器(用于登录注册与数据库打交道的后台服务器)建议使用raid0或raid5提升磁盘读写效率
RAID 10练习 环境:准备四块10G的磁盘
1 2 3 4 5 6 7 8 [root@RockyLinux ~]# fdisk -l | grep sd Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors Disk /dev/sda: 40 GiB, 42949672960 bytes, 83886080 sectors /dev/sda1 * 2048 2099199 2097152 1G 83 Linux /dev/sda2 2099200 83886079 81786880 39G 8e Linux LVM Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
学习mdadm命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 如果提示命令不存在需要对此软件进行安装 yum install mdadm -y 创建raid 10 [root@RockyLinux ~]# mdadm -Cv /dev/md0 -a yes -n 4 -l 10 /dev/sdb /dev/sdc /dev/sdd /dev/sde mdadm: layout defaults to n2 mdadm: layout defaults to n2 mdadm: chunk size defaults to 512K mdadm: size set to 10476544K mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. 参数说明: -C:表示创建RAID阵列 -v:显示创建的过程 /dev/md0:表示raid阵列的名字 -a yes:自动创建阵列设备文件 -n 4:表示用4块硬盘创建阵列 -l 10:表示指定raid的级别 最后跟上加入磁盘阵列的四块硬盘设备 针对磁盘阵列设备进行文件系统格式化 mkfs.xfs /dev/md0 [root@RockyLinux ~]# mkfs.xfs /dev/md0 log stripe unit (524288 bytes) is too large (maximum is 256KiB) log stripe unit adjusted to 32KiB meta-data=/dev/md0 isize=512 agcount=16, agsize=327296 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 bigtime=1 inobtcount=1 nrext64=0 data = bsize=4096 blocks=5236736, imaxpct=25 = sunit=128 swidth=256 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=16384, version=2 = sectsz=512 sunit=8 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 Discarding blocks...Done. 针对分区进行目录挂载,使用磁盘分区。需要先新建一个目录用于和阵列分区挂载 [root@RockyLinux ~]# mkdir /raidmnt 使用mount命令进行挂载 [root@RockyLinux ~]# mount /dev/md0 /raidmnt/ 检查挂载情况 [root@RockyLinux ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs tmpfs 783M 13M 770M 2% /run /dev/mapper/rl-root xfs 35G 2.9G 33G 9% / /dev/sda1 xfs 960M 289M 672M 31% /boot tmpfs tmpfs 392M 4.0K 392M 1% /run/user/0 /dev/md0 xfs 20G 176M 20G 1% /raidmnt [root@RockyLinux ~]# mount -l /dev/md0 on /raidmnt type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,sunit=1024,swidth=2048,noquota) 检查raid 10的详细信息 [root@RockyLinux ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Sep 16 14:17:03 2025 Raid Level : raid10 Array Size : 20953088 (19.98 GiB 21.46 GB) Used Dev Size : 10476544 (9.99 GiB 10.73 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Tue Sep 16 14:25:20 2025 State : clean Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Consistency Policy : resync Name : RockyLinux:0 (local to host RockyLinux) UUID : 92afac70:178cd13c:96fee32c:b0ad05de Events : 17 Number Major Minor RaidDevice State 0 8 16 0 active sync set-A /dev/sdb 1 8 32 1 active sync set-B /dev/sdc 2 8 48 2 active sync set-A /dev/sdd 3 8 64 3 active sync set-B /dev/sde 自动挂载raid设备 [root@RockyLinux ~]# echo "/dev/md0 /raidmnt xfs defaults 0 0" >> /etc/fstab [root@RockyLinux ~]# tail -1 /etc/fstab /dev/md0 /raidmnt xfs defaults 0 0
raid故障 模拟挂掉一块硬盘,从raid 10的四块硬盘组中,剔除一块磁盘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 剔除raid 10中一块硬盘的命令 [root@RockyLinux ~]# mdadm /dev/md0 -f /dev/sdd mdadm: set /dev/sdd faulty in /dev/md0 检查raid 10的状态 [root@RockyLinux ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Sep 16 14:17:03 2025 Raid Level : raid10 Array Size : 20953088 (19.98 GiB 21.46 GB) Used Dev Size : 10476544 (9.99 GiB 10.73 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Tue Sep 16 14:50:44 2025 State : clean, degraded Active Devices : 3 Working Devices : 3 Failed Devices : 1 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Consistency Policy : resync Name : RockyLinux:0 (local to host RockyLinux) UUID : 92afac70:178cd13c:96fee32c:b0ad05de Events : 19 Number Major Minor RaidDevice State 0 8 16 0 active sync set-A /dev/sdb 1 8 32 1 active sync set-B /dev/sdc - 0 0 2 removed 3 8 64 3 active sync set-B /dev/sde 2 8 48 - faulty /dev/sdd 通过写入操作对移除后的磁盘阵列进行验证,验证后会发现整个raid 10的使用
新增磁盘到raid 重新加入磁盘阵列,必须取消raid磁盘阵列的挂载
1 [root@RockyLinux ~]# umount /dev/md0
重新添加新的硬盘,加入至/dev/md0磁盘阵列组中
1 2 [root@RockyLinux ~]# mdadm /dev/md0 -a /dev/sdd mdadm: Cannot open /dev/sdd: Device or resource busy
此时提示设备繁忙,需要对服务器进行重启,重启后再对raid磁盘阵列进行卸载操作后再加入
1 2 3 [root@RockyLinux ~]# umount /dev/md0 [root@RockyLinux ~]# mdadm /dev/md0 -a /dev/sdd mdadm: added /dev/sdd
加入后的设备会进行重构,Rebuild Status : 24% complete为重构进度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@RockyLinux ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Sep 16 14:17:03 2025 Raid Level : raid10 Array Size : 20953088 (19.98 GiB 21.46 GB) Used Dev Size : 10476544 (9.99 GiB 10.73 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Tue Sep 16 15:03:05 2025 State : clean, degraded, recovering Active Devices : 3 Working Devices : 4 Failed Devices : 0 Spare Devices : 1 Layout : near=2 Chunk Size : 512K Consistency Policy : resync Rebuild Status : 24% complete Name : RockyLinux:0 (local to host RockyLinux) UUID : 92afac70:178cd13c:96fee32c:b0ad05de Events : 30 Number Major Minor RaidDevice State 0 8 16 0 active sync set-A /dev/sdb 1 8 32 1 active sync set-B /dev/sdc 4 8 48 2 spare rebuilding /dev/sdd 3 8 64 3 active sync set-B /dev/sde
稍等一段时间之后即可构建完毕
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@RockyLinux ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Sep 16 14:17:03 2025 Raid Level : raid10 Array Size : 20953088 (19.98 GiB 21.46 GB) Used Dev Size : 10476544 (9.99 GiB 10.73 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Tue Sep 16 15:05:20 2025 State : clean Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Consistency Policy : resync Name : RockyLinux:0 (local to host RockyLinux) UUID : 92afac70:178cd13c:96fee32c:b0ad05de Events : 44 Number Major Minor RaidDevice State 0 8 16 0 active sync set-A /dev/sdb 1 8 32 1 active sync set-B /dev/sdc 4 8 48 2 active sync set-A /dev/sdd 3 8 64 3 active sync set-B /dev/sde
构建完毕后在对磁盘阵列进行挂载即可正常使用
1 2 3 4 5 6 7 8 9 10 [root@RockyLinux ~]# mount /dev/md0 /raidmnt [root@RockyLinux ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs tmpfs 783M 8.6M 774M 2% /run /dev/mapper/rl-root xfs 35G 2.9G 33G 9% / /dev/sda1 xfs 960M 289M 672M 31% /boot tmpfs tmpfs 392M 4.0K 392M 1% /run/user/0 /dev/md0 xfs 20G 176M 20G 1% /raidmnt
raid 10重启 先创建raid的配置文件
1 2 3 [root@RockyLinux ~]# echo DEVICE /dev/sd[b-e] > /etc/mdadm.conf [root@RockyLinux ~]# cat /etc/mdadm.conf DEVICE /dev/sdb /dev/sdc /dev/sdd /dev/sde
扫描磁盘阵列信息,追加到这个文件中
1 2 3 [root@RockyLinux ~]# cat /etc/mdadm.conf DEVICE /dev/sdb /dev/sdc /dev/sdd /dev/sde ARRAY /dev/md/0 metadata=1.2 UUID=92afac70:178cd13c:96fee32c:b0ad05de
取消raid 10的挂载
1 2 3 4 5 6 7 8 9 [root@RockyLinux ~]# umount /raidmnt [root@RockyLinux ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs tmpfs 783M 8.6M 774M 2% /run /dev/mapper/rl-root xfs 35G 2.9G 33G 9% / /dev/sda1 xfs 960M 289M 672M 31% /boot tmpfs tmpfs 392M 4.0K 392M 1% /run/user/0
停止raid 10
1 2 [root@RockyLinux ~]# mdadm -S /dev/md0 mdadm: stopped /dev/md0
检查磁盘阵列组信息,没有找到设备信息即为正常状态
1 2 [root@RockyLinux ~]# mdadm -D /dev/md0 mdadm: cannot open /dev/md0: No such file or directory
在存在配置文件的情况下,可以正常地启动raid 10
1 2 [root@RockyLinux ~]# mdadm -A /dev/md0 mdadm: /dev/md0 has been started with 4 drives.
此时就可以正常看到raid 10的信息了,并且对/dev/md0自动挂载了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@RockyLinux ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Sep 16 14:17:03 2025 Raid Level : raid10 Array Size : 20953088 (19.98 GiB 21.46 GB) Used Dev Size : 10476544 (9.99 GiB 10.73 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Tue Sep 16 15:16:00 2025 State : clean Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Consistency Policy : resync Name : RockyLinux:0 (local to host RockyLinux) UUID : 92afac70:178cd13c:96fee32c:b0ad05de Events : 44 Number Major Minor RaidDevice State 0 8 16 0 active sync set-A /dev/sdb 1 8 32 1 active sync set-B /dev/sdc 4 8 48 2 active sync set-A /dev/sdd 3 8 64 3 active sync set-B /dev/sde
重新启动后再对/dev/md0重新进行挂载即可正常使用raid阵列了。
raid 10删除 卸载/dev/md0设备
1 [root@RockyLinux ~]# umount /dev/md0
停止raid服务
1 2 [root@RockyLinux ~]# mdadm -S /dev/md0 mdadm: stopped /dev/md0
卸载raid 10中所有的磁盘信息
1 2 3 4 [root@RockyLinux ~]# mdadm --misc --zero-superblock /dev/sdb [root@RockyLinux ~]# mdadm --misc --zero-superblock /dev/sdc [root@RockyLinux ~]# mdadm --misc --zero-superblock /dev/sdd [root@RockyLinux ~]# mdadm --misc --zero-superblock /dev/sde
删除raid的配置文件
1 [root@RockyLinux ~]# rm -f /etc/mdadm.conf
再清除/etc/fstab文件中关于raid阵列的挂载配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@RockyLinux ~]# sed -r '/^.*\/dev\/md0/d' /etc/fstab # # Created by anaconda on Sun Jul 13 02:58:34 2025 # # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info. # # units generated from this file. # /dev/mapper/rl-root / xfs defaults 0 0 UUID=e7d1373d-724e-440b-aba2-c6c4e7c6edad /boot xfs defaults 0 0 # /dev/mapper/rl-swap none swap defaults 0 0
raid与备份盘 创建raid磁盘阵列
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@RockyLinux ~]# mdadm -Cv /dev/md0 -n 3 -l 5 -x 1 /dev/sdb /dev/sdc /dev/sdd /dev/sde mdadm: layout defaults to left-symmetric mdadm: layout defaults to left-symmetric mdadm: chunk size defaults to 512K mdadm: size set to 10476544K mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. 参数说明: -n 指定3块硬盘 -l 指定raid的级别是raid 5 -x 1 指定一个备份盘 /dev/sd[b-e] 代表指定使用的四块硬盘
检查raid阵列组的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 [root@RockyLinux ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Sep 16 15:51:10 2025 Raid Level : raid5 Array Size : 20953088 (19.98 GiB 21.46 GB) Used Dev Size : 10476544 (9.99 GiB 10.73 GB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Tue Sep 16 15:53:54 2025 State : clean Active Devices : 3 Working Devices : 4 Failed Devices : 0 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Consistency Policy : resync Name : RockyLinux:0 (local to host RockyLinux) UUID : bf1c4ea9:9034d333:9a1a0f3d:a1f942ce Events : 18 Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 4 8 48 2 active sync /dev/sdd 3 8 64 - spare /dev/sde
针对阵列组进行格式化文件系统
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@RockyLinux ~]# mkfs.xfs -f /dev/md0 log stripe unit (524288 bytes) is too large (maximum is 256KiB) log stripe unit adjusted to 32KiB meta-data=/dev/md0 isize=512 agcount=16, agsize=327296 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 bigtime=1 inobtcount=1 nrext64=0 data = bsize=4096 blocks=5236736, imaxpct=25 = sunit=128 swidth=256 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=16384, version=2 = sectsz=512 sunit=8 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0
开始挂载使用阵列组分区
1 2 3 4 5 [root@RockyLinux ~]# mount /dev/md0 /raidmnt [root@RockyLinux ~]# mount -l | grep md0 /dev/md0 on /raidmnt type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,sunit=1024,swidth=2048,noquota) [root@RockyLinux ~]# df -hT | grep md0 /dev/md0 xfs 20G 176M 20G 1% /raidmnt
从磁盘阵列组中删掉一块硬盘并检查阵列情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 [root@RockyLinux ~]# mdadm /dev/md0 -f /dev/sdb mdadm: set /dev/sdb faulty in /dev/md0 [root@RockyLinux ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Sep 16 15:51:10 2025 Raid Level : raid5 Array Size : 20953088 (19.98 GiB 21.46 GB) Used Dev Size : 10476544 (9.99 GiB 10.73 GB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Tue Sep 16 16:03:36 2025 State : clean, degraded, recovering Active Devices : 2 Working Devices : 3 Failed Devices : 1 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Consistency Policy : resync Rebuild Status : 9% complete Name : RockyLinux:0 (local to host RockyLinux) UUID : bf1c4ea9:9034d333:9a1a0f3d:a1f942ce Events : 21 Number Major Minor RaidDevice State 3 8 64 0 spare rebuilding /dev/sde 1 8 32 1 active sync /dev/sdc 4 8 48 2 active sync /dev/sdd 0 8 16 - faulty /dev/sdb
会看到/dev/sde作为备用盘顶替了/dev/sdb,并开始重新构建,构建好后即可使用。
LVM 逻辑卷管理技术,可以将一个或者多个硬盘在逻辑上进行合并,相当于一个大的硬盘去使用,当硬盘空间不够了的话,可以直接去其他硬盘中拿来容量去使用,这就是一个动态的磁盘容量管理技术。
lvm原理lvm动态扩容大小其实就是通过互相交换PE的过程达到能够弹性扩容分区大小。
想要减少空间容量,就是剔除PE的大小。
想要扩大容量,就是把其他的PE添加到自己的LV当中。
PE默认大小一般都是4M,LVM最多是可以创建出65534个PE,因此LVM最大的VG卷组单位是256G。
PE其实是LVM最小的存储单位,类似于操作系统的block(大小4k)
LV逻辑卷的概念(理解为普通的分区概念,如/dev/sda,/dev/sdb)
lvm的使用方式
基于分区形式创建lvm,硬盘的多分区由lvm统一进行管理为卷组,可以弹性的调整卷组的大小,加入新硬盘可以充分的利用磁盘容量。文件系统是创建在逻辑卷上,逻辑卷可以根据需求改变大小(总容量控制在卷组中)。
基于硬盘创建lvm,多块硬盘做成逻辑卷,将整个逻辑卷统一管理,对分区进行动态扩容。
lvm的常见名词
PP(physical parttion)物理分区,lvm直接创建在物理分区之上。
PV(physical volume)物理卷,处于lvm的最底层,一般一个PV对应一个PP。
VG(volume group)卷组,卷组创建在PV之上,可以分为多个PV。
PE(physical extends)物理区域,PV中可以用于分配的最小存储单位,同一个VG所有的PV中的PE大小相同,如1M,2M。
LE(logical extends)逻辑扩展单元,LE是组成LV的基本单元,一个LE对应了一个PE。
LV(logical volume)逻辑卷,创建在VG之上,是一个可以动态扩容的分区概念。
lvm优点
lvm的文件系统可以跨越多个磁盘,分区大小不受磁盘容量限制。
可以在系统运行中,直接动态扩容文件系统大小。
可以直接增加新的硬盘,到lvm的vg卷组中。
lvm动态调整空间使用lvm创建流程:
物理分区阶段,针对物理磁盘或者分区,进行fdisk格式化,修改系统的id,默认是83,改为8e类型,是lvm类型。
pv阶段,通过pvcreate,pvdisplay将Linux分区改为物理卷PV。
创建VG的阶段,通过vgcreate,vgdisplay将创建好的物理卷PV改为物理卷组VG。
创建LV,通过lvcreate将卷组分为若干个逻辑卷。
lvm的管理常见命令
命令
解释
PV物理卷
pvcreate
创建物理卷
pvscan
扫描物理卷信息
pvdisplay
显示各个物理卷详细参数
pvremove
删除物理卷
VG卷组
vgcreate
创建物理卷组
vgscan
扫描物理卷组信息
vgdisplay
显示各个物理卷组详细参数
vgreduce
缩小卷组,把物理卷从卷组中移除
vgextend
扩大卷组,把某个新的物理卷加到卷组中
vgremove
删除整个卷组
LV逻辑卷
lvcreate
创建逻辑卷
lvscan
扫描逻辑卷信息
lvdisplay
显示各个逻辑卷详细参数
lvreduce
缩小逻辑卷
lvextend
扩大逻辑卷
lvremove
删除逻辑卷
lvm实践
实验需要4块硬盘,本机中我已添加了/dev/sd[b-e]四块硬盘,选择sdb和sdc创建物理卷添加至卷组。
1 2 3 [root@RockyLinux ~]# pvcreate /dev/sdb /dev/sdc Physical volume "/dev/sdb" successfully created. Physical volume "/dev/sdc" successfully created.
创建卷组
1 2 [root@RockyLinux ~]# vgcreate qinhuaivg /dev/sdb /dev/sdc Volume group "qinhuaivg" successfully created
分别查看PV和VG的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@RockyLinux ~]# pvs | grep qinhuaivg /dev/sdb qinhuaivg lvm2 a-- <10.00g <10.00g /dev/sdc qinhuaivg lvm2 a-- <10.00g <10.00g [root@RockyLinux ~]# pvscan | grep qinhuaivg PV /dev/sdb VG qinhuaivg lvm2 [<10.00 GiB / <10.00 GiB free] PV /dev/sdc VG qinhuaivg lvm2 [<10.00 GiB / <10.00 GiB free] [root@RockyLinux ~]# vgs VG #PV #LV #SN Attr VSize VFree qinhuaivg 2 0 0 wz--n- 19.99g 19.99g rl 1 2 0 wz--n- <39.00g 0 [root@RockyLinux ~]# vgscan Found volume group "rl" using metadata type lvm2 Found volume group "qinhuaivg" using metadata type lvm2
尝试扩容或缩减VG卷组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 扩容命令 第一步,买了一个新硬盘,然后创建物理卷 [root@RockyLinux ~]# pvcreate /dev/sdd Physical volume "/dev/sdd" successfully created. pvs检查物理卷的信息 [root@RockyLinux ~]# pvs PV VG Fmt Attr PSize PFree /dev/sda2 rl lvm2 a-- <39.00g 0 /dev/sdb qinhuaivg lvm2 a-- <10.00g <10.00g /dev/sdc qinhuaivg lvm2 a-- <10.00g <10.00g /dev/sdd lvm2 --- 10.00g 10.00g 第二步,把新创建的sdd物理卷加入扩容到卷组qinhuaivg中 [root@RockyLinux ~]# vgextend qinhuaivg /dev/sdd Volume group "qinhuaivg" successfully extended [root@RockyLinux ~]# vgs VG #PV #LV #SN Attr VSize VFree qinhuaivg 3 0 0 wz--n- <29.99g <29.99g rl 1 2 0 wz--n- <39.00g 0 第三步,缩容,将/dev/sdd从物理卷组中移除 [root@RockyLinux ~]# vgreduce qinhuaivg /dev/sdd Removed "/dev/sdd" from volume group "qinhuaivg" 第四步,删除/dev/sdd的物理卷 [root@RockyLinux ~]# pvremove /dev/sdd Labels on physical volume "/dev/sdd" successfully wiped.
创建逻辑卷
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@RockyLinux ~]# lvcreate -n qinhuailv -L +5G qinhuaivg Logical volume "qinhuailv" created. [root@RockyLinux ~]# lvdisplay --- Logical volume --- LV Path /dev/qinhuaivg/qinhuailv LV Name qinhuailv VG Name qinhuaivg LV UUID oHFi90-w7FA-Kt51-yh48-8XrT-AHUk-YyVkYs LV Write Access read/write LV Creation host, time RockyLinux, 2025-09-16 18:44:13 +0800 LV Status available # open 0 LV Size 5.00 GiB Current LE 1280 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:2
对刚创建的lv1逻辑卷进行格式化文件系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@RockyLinux ~]# mkfs.xfs /dev/qinhuaivg/qinhuailv meta-data=/dev/qinhuaivg/qinhuailv isize=512 agcount=4, agsize=327680 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 bigtime=1 inobtcount=1 nrext64=0 data = bsize=4096 blocks=1310720, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=16384, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 Discarding blocks...Done. [root@RockyLinux ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 40G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 39G 0 part ├─rl-root 253:0 0 35.1G 0 lvm / └─rl-swap 253:1 0 3.9G 0 lvm sdb 8:16 0 10G 0 disk └─qinhuaivg-qinhuailv 253:2 0 5G 0 lvm sdc 8:32 0 10G 0 disk sdd 8:48 0 10G 0 disk sde 8:64 0 10G 0 disk
向逻辑卷qinhuailv中进行挂载以及数据写入(就可以当作一个普通分区来使用了)
1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux ~]# mkdir /lvmnt [root@RockyLinux ~]# mount /dev/qinhuaivg/qinhuailv /lvmnt/ [root@RockyLinux ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs tmpfs 783M 8.6M 774M 2% /run /dev/mapper/rl-root xfs 35G 2.9G 33G 9% / /dev/sda1 xfs 960M 289M 672M 31% /boot tmpfs tmpfs 392M 4.0K 392M 1% /run/user/0 /dev/mapper/qinhuaivg-qinhuailv xfs 5.0G 68M 4.9G 2% /lvmnt
针对lv逻辑卷的扩容操作,只要卷组中的容量够用,就可以对逻辑卷扩容
1 2 3 4 5 6 7 8 先卸载lv的设备 [root@RockyLinux ~]# umount /lvmnt 对lv逻辑卷进行扩容 [root@RockyLinux ~]# lvextend -L +10G /dev/qinhuaivg/qinhuailv Size of logical volume qinhuaivg/qinhuailv changed from 5.00 GiB (1280 extents) to 15.00 GiB (3840 extents). Logical volume qinhuaivg/qinhuailv successfully resized. 挂载逻辑卷开始使用 [root@RockyLinux ~]# mount /dev/qinhuaivg/qinhuailv /lvmnt/
还得调整xfs文件系统的大小才能识别到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@RockyLinux ~]# xfs_growfs /dev/qinhuaivg/qinhuailv meta-data=/dev/mapper/qinhuaivg-qinhuailv isize=512 agcount=4, agsize=327680 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 bigtime=1 inobtcount=1 nrext64=0 data = bsize=4096 blocks=1310720, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=16384, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 data blocks changed from 1310720 to 3932160 [root@RockyLinux ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 40G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 39G 0 part ├─rl-root 253:0 0 35.1G 0 lvm / └─rl-swap 253:1 0 3.9G 0 lvm sdb 8:16 0 10G 0 disk └─qinhuaivg-qinhuailv 253:2 0 15G 0 lvm /lvmnt sdc 8:32 0 10G 0 disk └─qinhuaivg-qinhuailv 253:2 0 15G 0 lvm /lvmnt sdd 8:48 0 10G 0 disk sde 8:64 0 10G 0 disk [root@RockyLinux ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs tmpfs 783M 8.6M 774M 2% /run /dev/mapper/rl-root xfs 35G 2.9G 33G 9% / /dev/sda1 xfs 960M 289M 672M 31% /boot tmpfs tmpfs 392M 4.0K 392M 1% /run/user/0 /dev/mapper/qinhuaivg-qinhuailv xfs 15G 140M 15G 1% /lvmnt
lvm删除
1 2 3 4 5 6 7 8 9 [root@RockyLinux ~]# umount /lvmnt [root@RockyLinux ~]# lvremove /dev/qinhuaivg/qinhuailv Do you really want to remove active logical volume qinhuaivg/qinhuailv? [y/n]: y Logical volume "qinhuailv" successfully removed. [root@RockyLinux ~]# vgremove qinhuaivg Volume group "qinhuaivg" successfully removed [root@RockyLinux ~]# pvremove /dev/sdb /dev/sdc Labels on physical volume "/dev/sdb" successfully wiped. Labels on physical volume "/dev/sdc" successfully wiped.
软硬链接 ln命令 ln命令是单词link缩写,功能是创建文件之间的链接(make links between files),链接类型包括:
硬链接 hard link:创建语法ln 源文件 目标文件,硬链接生成的是普通文件
软链接 symbolic link:创建语法是ln -s 源文件 目标文件,生成符号链接文件
命令参数
解释
ln无参数
创建硬链接
-s
创建软连接(符号链接)
-b
删除,覆盖以前建立的软链接
-f
强制执行
-i
交互模式,文件存在则提示用户是否覆盖
-n
把符号链接视为一般目录
-v
显示详细的处理过程
-d
允许超级用户制作目录的硬链接
修改软链接
快捷方式删除不会影响源文件
可以生成多个快捷方式,斤斤都是指向了源文件
源文件如果删除,快捷方式则失效了
快捷方式还可以针对文件夹创建,也可以进入软链接类型的文件夹
使用readlink查看软链接文件本身的内容,存放的是源文件的路径
inode与硬链接 操作系统中专门用于管理和存储文件的信息软件称之为文件系统,文件系统将文件的元信息(文件创建者,日期,大小等,可以通过stat命令查看元信息)存储在一个称之为inode的区域,中文是索引节点
查看文件inode号
1 2 3 4 5 6 [root@RockyLinux ~]# ls -li total 4 67960081 -rw-------. 1 root root 795 Jul 13 11:15 anaconda-ks.cfg 67241218 drwxr-xr-x 3 root root 54 Sep 5 23:15 frp 571721 drwxr-xr-x 6 root root 50 Sep 13 15:19 linuxtest 67244060 drwxr-xr-x 2 root root 34 Sep 13 20:56 shells
通过ls -l查看到的数据,唯独文件名不是Inode存储的数据信息
Inode存储的信息不限于:
文件大小
属主
用户组
文件权限
文件类型
修改时间
硬盘在格式化的时候,系统自动的分为了2部分,一个部分是元数据区域,存放文件的inode信息,一个是文件数据内容区域
每个inode的大小,都是在格式化分区的时候决定好的,默认是以128字节或是256字节。
一般情况下,文件名和inode号是一对一的。
硬链接不支持链接到目录文件夹且不可跨文件系统。
软链接可以针对目录文件夹操作且可以跨文件系统。
软链接的inode号是不一样的,代表软链接文件是两个单个的个体,硬链接的inode号是一样的。
软硬连接综合比较 删除软链接(硬链接)对源文件和硬链接(软链接)无影响
删除源文件,对硬链接也是无影响的,但是对软链接有影响
只有删除源文件和所有硬链接文件的链接数就为0了,此时文件数据丢失
硬链接和源文件都具有相同的inode码,可以理解为:一个超市有多个入口(硬链接),都指向同一个超市(源文件)
软链接和源文件的inode码不同,因此是两个单独的文件
进程 概念 Linux下存在process(进程)和thread(线程)。计算机的核心是CPU,承担整个系统的计算任务。
进程就是Linux系统上的一个任务资源单位,进程就好比是一个工厂的车间,一个工厂可能有多个车间,每一个车间代表CPU正在处理的任务,某一个时刻,CPU总是运行一个进程,其他进程处于非运行的状态。
在一个车间内,想要完成某一项工作,必须得有多个工人协同完成这个任务,每一个车间的工人可以理解为Linux系统中的工作线程。
车间内是由存放空间的,可以理解为Linux的进程单位,是有存储空间的,在进程空间里线程共享这个资源。
进程内的空间容量大小各不相同,有的空间可以容下多个线程,某一内存数据可以被多个线程同时使用也有可能只给一个线程使用。
进程内有一个线程正在使用一块内存数据,其他线程必须等待这个线程处理内存数据完毕才能使用内存。
线程1在使用内存数据的时候,线程2不愿意等待直接想去抢夺这一块内存数据,就有可能引发混乱,造成数据冲突崩溃。这个时候线程可以针对内存数据加一把锁,其他进程看到这个内存数据上锁后只有等待上锁线程使用完内存才能使用。
互斥锁:防止线程对内存数据抢夺的作用,方式多个线程同时读写同一块内存数据。
Linux是一个多用户,多任务的操作系统,支持多进程多线程。
多进程——Linux操作系统内可以同时有多个进程在工作。
多线程——一个进程内有多个线程在运行。
单线程——一个进程内只有一个线程在运行。
进程通信方式
管道pipe :管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。命名管道FIFO :有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。消息队列MessageQueue :消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。共享存储SharedMemory :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。信号量Semaphore :信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。套接字Socket :套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
ps命令 ps命令用于报告当前系统的进程状态的命令,主要用于查询进程信息,和kill命令搭配,进行对进程的管理,杀死。
1 2 3 4 5 6 7 8 9 10 11 12 ps [options] (功能参数) 要操作的对象 [root@RockyLinux ~]# ps PID TTY TIME CMD 1274000 pts/0 00:00:00 bash 1460201 pts/0 00:00:00 ps 参数详解 PID 代表这个进程对应的id号码 CMD 正在执行的系统命令 TTY 进程所属的控制台号码 TIME 进程所使用CPU的总时间
ps组合命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 -ef 显示出Linux机器所有详细的进程信息 -e 列出系统所有运行的进程 -f 显示ID UID PID PPID C STIME TTY TIME CMD UID:这个进程是哪个用户执行的命令 PID:进程的标识号,用于启停进程 PPID:父进程的标识号 C:表示CPU使用的资源百分比 STIME:表示进程开始执行的时间 TTY:该进程在哪个终端上执行的 TIME:该进程使用的CPU总时长 CMD:用户执行某条命令,产生的进程信息 ps aux 参数a显示当前终端下的所有进程,包括其他用户的进程信息。 u以用户为主的格式显示进程情况 x显示所有进程 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.3 105656 13696 ? Ss Sep16 0:13 /usr/lib/systemd/systemd rhgb --switched-root --system --deserialize 31 参数详解 USER 进程的属主 PID 进程ID号 % CPU cpu的百分比占用情况 % MEM 内存的的百分比占用情况 VSZ 该进程使用多个swap内存单位 RSS 表示进程所占用的内存量 TTY 这个进程所在的终端信息 START 表示进程此时的状态 S:终端睡眠中,可被唤醒 s:这个进程中含有子进程,就会显示有s R:这个进程运行中 D:这个进程不可中断睡眠 T:表示进程已停止 Z:进程已经是僵尸进程了,父进程异常崩溃 +:前台进程 N:低优先级进程 <:高优先级进程 L:该进程已被锁定 TIME:进程运行的时间 CMD:进程执行的命令是什么 ps -eH 显示父进程,子进程的目录结构信息 查看进程树命令 pstree 如果未安装可使用yum install psmisc -y pgrep命令 通过程序的名字取查询相关进程,一般用来判断进程是否存活
ps命令的参数分为两种系统形式
1 2 3 4 5 第一种,不带减号的参数 ps ef e列出进程信息时,添加每个进程所在的环境变量 f以ASCII码字符显示进程间的关系 第二种,带减号的参数 ps -e -f -e的作用是显示出所有进程的信息 -f就是显示出UID PPID C STIME等信息
进程杀死 kill命令 kill发送相关信号给进程,达到不同的停止效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 kill 参数 -l 列出所有的杀死、终止信号 [root@RockyLinux ~]# kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX 常用信号如下: 1) SIGHUP 挂起进程,终端突然掉线,用户突然退出 2) SIGINT 中断信号,一般常用ctrl + c发送信号2 3) SIGQUIT 退出信号,一般用ctrl + \发出信号3 9) SIGKILL 强制中断信号,一般用于立即杀死某些进程 15) SIGTERM kill默认使用的就是15信号,终止进程 20) SIGTSTP 暂停进程,通常是组合键ctrl + z发出暂停信号
终止进程
1 2 kill pid 发送15信号终止进程 kill -9 pid 立即停止进程,危险命令可以杀死所有的进程,如僵尸进程等
特殊信号
1 2 3 4 kill的特殊信号0,常在shell脚本中 kill -0 $pid 表示不发送任何的信号给pid,但是会对这个pid进行检查,如果执行结果是0表示此进程存在,如果结果为1,进程不存在(信号0可以判断pid是否存在) kill -0 pid 进程id存在的话,不做任何事,可以检测pid是否存活 echo $? shell的特殊变量,取出上一次命令的执行结果,为0表示命令正确,不为0都是错误状态码
killall命令 kill杀死进程,只能杀死一个pid进程,通过killall可以直接通过名字杀死进程
killall vim 杀死所有的vim进程
killall nginx 终止所有的nginx进程
pkill命令 pkill可以通过进程名字杀死多个进程,killall杀死进程可能一次杀不死,因为进程中可能含有子进程,killall要杀死很多次。
pkill可以直接杀死父进程和子进程。
eg:
pkill nginx 杀死所有的nginx进程
通过终端杀死进程 1 2 3 4 5 6 7 8 9 10 11 在控制台中输入w命令查看登录服务器的终端 [root@RockyLinux ~]# w 14:33:17 up 23:32, 2 users, load average: 0.23, 0.20, 0.18 USER TTY LOGIN@ IDLE JCPU PCPU WHAT root pts/0 13:40 1.00s 0.01s 0.00s w root pts/1 13:40 53:09 8.59s 8.57s top 通过pkill命令终止终端 pikll -t pts/0 将终端踢下线 pikll -9 -t pts/0
top命令 1 2 3 4 5 6 7 top - 15:49:24 up 1 day, 49 min, 2 users, load average: 0.20, 0.19, 0.18 Tasks: 144 total, 1 running, 143 sleeping, 0 stopped, 0 zombie % Cpu(s): 3.5 us, 5.2 sy, 0.0 ni, 90.8 id , 0.0 wa, 0.2 hi, 0.3 si, 0.0 st MiB Mem : 3911.7 total, 3325.4 free, 476.1 used, 353.1 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 3435.6 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15:49:24 up 当前的机器时间
1 day, 49 min 当前系统运行了多久
load average: 0.20, 0.19, 0.18 系统的平均负载情况,分别是1分钟,5分钟,15分钟现实的平均值(值越小,负载越低)
Tasks: 144 total, 1 running, 143 sleeping, 0 stopped, 0 zombie 总共的进程任务情况
%Cpu(s): 3.5 us, 5.2 sy, 0.0 ni, 90.8 id, 0.0 wa, 0.2 hi, 0.3 si, 0.0 st cpu的使用百分比情况
us 用户占用的cpu百分比情况
sy 系统占用的cpu百分比情况
ni 用户进程空间占用的cpu百分比情况
id 空间cpu百分比情况
wa 等待输入输出的cpu百分比情况
top命令的第二大板块,动态的进程信息:
PID USER PR NI VIRT RES S %CPU %MEM TIME+ COMMAND
PID 进程id号,可以对它启停进程
USER 执行进程的用户是谁
PR 进程的优先级高低
NI nice值,越高表示优先级越高
VIRT 进程使用的虚拟内存总量 VIRT=swap+RES
RES 进程使用的物理内存大小
SHR 共享内存大小,单位是kb
%CPU %MEM cpu和内存的使用情况
top命令的实际使用 进入top命令后,输入数字1指令,表示查看Linux的逻辑cpu个数
按照内存使用情况排序:进入top后输入大写的M指定,内存使用量,从大到小排序
top显示进程的绝对路径
设置top进程的刷新时间
设置top命令的刷新次数
指定查看某一个进程的信息
指定某一列高亮显示
1 2 3 4 输入z打开颜色 输入x某一列高亮 输入b某一列颜色加粗 符号<或者>对高亮列进行移动
nohup后台运行 nohup命令可以将程序以忽略挂起信号的形式在后台运行,也就是被运行的程序输出的结果不打印到终端。无论是否将nohup命令的输出重定向到终端,nohup命令执行的结果都会写入到当前目录的nohup.out文件中。如果当前目录的nohup.out文件禁止写入数据,nohup的命令结果会自动输出到$HOME/nohup.out文件中
1 2 3 4 5 6 7 8 9 nohup 执行的命令 1.nohup直接加上要执行的命令,即使终端关闭,程序也会在后台继续运行,但是程序会卡在前台 2.一般使用nohup不会敲完命令后,直接关闭窗口,而是希望能够继续运行命令行,只需要在命令结尾加上&符号即可 nohup 执行的命令 & 3.不显示命令的执行结果,直接将所有的运行日志输出到特定的文件当中 nohup 执行命令 > 特定文件路径 2>&1 &
shell shell脚本介绍 当命令或者程序语句写在文件中,我们执行文件,读取其中的代码,这个程序文件就称之为shell脚本。
当shell脚本里定义多条Linux命令以及循环控制语句,然后将这些Linux命令一次性执行完毕,执行脚本文件的方式称之为非交互式。
规则:
在Linux系统中,shell脚本或者称之为(bash shell程序)通常都是vim编辑,由Linux命令、bash shell指令、逻辑控制语句和注释信息组成。
Shebang 在计算机程序中,shebang指的是出现在文本文件的第一行前两个字符#!。
在Unix系统中,程序会分析shebang后边的内容,作为解释器的指令。
以#!/bin/sh开头的文件,程序会在执行的时候调用/bin/sh,也就是bash解释器
以#!/usr/bin/python开头的文件,代表指定python解释器去执行
以#!/usr/bin/env解释器名称,是一种在不同平台上都能找到解释器的办法
注意事项
如果脚本未指定shebang,脚本执行的时候,默认用当前shell去解释脚本,即$SHELL
如果shebang指定了可执行的解释器,如/bin/bash /usr/bin/python,脚本在执行的时候,文件名会作为参数传递给解释器
如果#!指定的解释程序没有可执行权限,则会报错”bad interpreter:Permission denied”
如果#!指定的解释程序不是一个可执行文件,那么指定的解释程序会被忽略,转而交给当前的SHELL去执行这个脚本
如果#!指定的解释程序不存在,那么会报错”bad interpreter:No such file or directory”
#!之后的解释程序,需要写其绝对路径(如:#!/bin/bash),它是不会自动到$PATH中寻找解释器的如果使用”bash test.sh”这样的命令来执行脚本,那么#!这一行会被忽略掉,解释器当然是用命令行中显式指定的bash
脚本注释
在shell脚本中,#后面的内容代表注释掉的内容,提供给开发者或者使用者观看,胸痛会忽略此行
注释可以单独写一行,也可以跟在命令后面
尽量保持按写注释的习惯,便于以后回顾代码的含义。
执行shell脚本的方式
bash script.sh或sh script.sh,文件本身没权限执行,没x权限,则使用的方法,或脚本未指定shebang重点推荐的方法。使用绝对/相对路径执行脚本,需要文件含有x权限。
source script.sh或者. script.sh,代表执行的含义,source等于 .少见的用法sh < script.sh
shell和运维 shell脚本语言很适合处理纯文本类型数据,且Linux的哲学思想就是一切皆文件,如日志、配置文件、文本、网页文件大多数都是纯文本类型,因此shell可以方便的进行文本处理,好比强大的Linux三剑客(grep、sed、awk)
shell脚本 shell脚本语言属于一种弱类型语言,无需声明变量类型,直接定义使用
强类型语言,必须先定义变量类型,确定是数字、字符串等,之后再赋予同类型的值
shell的优势 虽然诸多脚本编程语言,但是对于Linux操作系统内部应用而言,shell是最好的工具,Linux底层命令都支持shell语句,以及结合三剑客(grep、sed、awk)进行高级用法。
擅长系统管理脚本开发,如软件启停脚本、监控报警脚本、日志分析脚本
每个语言都有自己擅长的地方,扬长避短,达到高效运维的目的是最合适的。
shell变量 变量是暂时存储数据的地方,是一种数据标记。数据存储在内容空间,通过调用正确的变量名字,即可取出对应的值。
1 2 3 name="qinhuai" 变量类型,bash会默认把所有变量都认为是字符串。 bash变量是弱类型,无需事先声明类型,是将声明和赋值同时进行。
1 2 3 [root@RockyLinux ~]# name="qinhuai" [root@RockyLinux ~]# echo $name qinhuai
名称定义要做到见名知意且按照规则来,不得引用保留关键字(help检查保留字)
只能包含数字、字母、下划线
不能以数字开头
不能用标点符号
变量名严格区分大小写
1 2 3 4 5 6 7 8 9 10 11 12 13 有效变量名 NAME_QINHUAI _qinhuai qinhuai1 qinhuai2 qinhuai3 Qin_huai 无效的变量 ?qinhuai qin*huai 1qinhuai qin+huai
本地变量 ,只针对当前的shell进程,子shell读不到父shell的变量。
环境变量 ,也成为全局变量,针对当前shell以及任意子进程,环境变量也分为自定义、内置两种环境变量
局部变量 ,针对在shell函数或是shell脚本中定义
位置参数变量:用于shell脚本中传递的参数
特殊变量:shell内置的特殊功效变量
0:成功
1-255:错误码
变量赋值:varName=value
变量引用:${name}、$varName
双引号,能够识别特殊符号,变量名会替换位变量值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@RockyLinux ~]# n1="1" [root@RockyLinux ~]# n2="2" [root@RockyLinux ~]# echo "$n1" 1 [root@RockyLinux ~]# echo $n1 1 [root@RockyLinux ~]# echo '$n1' $ n1 [root@RockyLinux ~]# n3="$n1" [root@RockyLinux ~]# echo $n3 1 [root@RockyLinux ~]# n4='$n2' [root@RockyLinux ~]# echo $n4 $ n2
单引号,不能识别特殊符号,会识别成普通的字符串。
反引号,引用命令执行结果,等于$()用法
每次调用bash/sh解释器执行脚本都会开启一个子shell,因此不保留当前的shell变量,通过pstree命令检查进程树。
调用source或.符号是在当前shell环境加载脚本,因此保留变量。
1 2 3 4 5 6 [root@RockyLinux ~]# cat 变量引号.sh user1=`whoami` [root@RockyLinux ~]# sh 变量引号.sh [root@RockyLinux ~]# echo $user1 执行结果为空
环境变量设置 环境变量一般指的是用export内置命令导出的变量,用于定义shell的运行环境、保证shell命令的正确执行。
shell通过环境变量确定登录的用户名,PATH路径、文件系统等各种应用。
环境变量可以在命令行中临时创建,但是用户退出的shell终端,变量即丢失,如要永久生效,需要修改环境变量配置文件。
用户个人配置文件~/.bash_profile、~/.bashrc远程登录用户特有文件。
全局配置文件/etc/profile、/etc/bashrc,且系统建议最好创建在/etc/profile.d,而非直接修改主文件,修改全局配置文件,影响所有登录系统的用户。
检查系统环境变量的命令
set:输出所有变量,包括全局变量、局部变量。
env:只显示全局变量
declare:输出所有的变量,如同set。
export:显示和设置环境变量值
撤销环境变量
设置只读变量
readonly:只有shell结束,只读变量失效且该变量只能读不能修改。
1 2 直接readonly显示当前只读变量 readonly name="qinhuai"
bash多命令执行 1 [root@RockyLinux ~]# ls /etc/nginx/;cd /etc/nginx;cat ./nginx.conf
环境变量初始化加载顺序
特殊参数变量 shell的特殊变量,用在如脚本,函数传递参数使用,有如下特殊的位置参数变量
1 2 3 4 5 $ 0 获取shell脚本文件名,以及脚本路径 $ n 获取shell脚本的第n个参数,n在1~9之间,如$1 ,$2 ,$3 ...$9 ,大于9则需要写${10} ,参数空格隔开 $ $ * 获取shell脚本所有参数,不加引号等同于$@ 作用,加上引号"$*" 作用是接收所有参数为单个字符串,"$1 ,$2 ..." $ @ 不加引号效果同上,加上引号是接收所有参数为独立字符串,如"$1 " ,"$2 " ,"$3 " ...空格保留
实践
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 [root@RockyLinux ~]# cat special_var.sh # !/bin/bash echo '------------------------------------------------------------------------------------------------------' echo '特殊变量$0的实践' echo '文件的路径为:' $0 echo '------------------------------------------------------------------------------------------------------' echo '特殊变量$n的实践' echo '获取的第2个参数为:' $2 '获取的第5个参数为:' $5 echo '------------------------------------------------------------------------------------------------------' echo '特殊变量$#的实践' echo 'shell脚本的参数总数:' $# echo '------------------------------------------------------------------------------------------------------' echo '特殊变量$*的实践' echo '得到的参数:' $* echo '------------------------------------------------------------------------------------------------------' echo '特殊变量$@的实践' echo '得到的参数:' $@ echo '------------------------------------------------------------------------------------------------------' 运行脚本 [root@RockyLinux ~]# bash special_var.sh qin huai is a boy ------------------------------------------------------------------------------------------------------ 特殊变量$0的实践 文件的路径为: special_var.sh ------------------------------------------------------------------------------------------------------ 特殊变量$n的实践 获取的第2个参数为: huai 获取的第5个参数为: boy ------------------------------------------------------------------------------------------------------ 特殊变量$#的实践 shell脚本的参数总数: 5 ------------------------------------------------------------------------------------------------------ 特殊变量$*的实践 得到的参数: qin huai is a boy ------------------------------------------------------------------------------------------------------ 特殊变量$@的实践 得到的参数: qin huai is a boy ------------------------------------------------------------------------------------------------------
面试题
1 2 3 4 5 6 7 8 9 $ *和$@ 的区别? $ *和$@ 都表示传递给函数或者脚本的所有参数 当$*和$@不被双引号引号引用的时候,它们没有任何区别,都是将收到的每一个参数看做一份数据,彼此之间以空格来分隔 当时当它们都被双引号引用时就会出现差异化: "$*"会将所有的参数从整体上看作一份数据,而不是把每个参数都看作一份数据。 "$@"仍然将每个参数都看作一份数据,彼此之间是独立的。 比如传递了5个参数,那么对于"$*"来说,这个5个参数会合并到一起形成一份数据,它们之间是无法分割的; 而对于"$@"来说,这5个参数是相互独立的,它们是5份数据。 如果使用echo直接输出"$*"和"$@"做对比是看不出区别的,使用for循环来逐个输出数据,立即就能看出区别来了。
for循环对于"$*"和"$@"的实践
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # !/bin/bash echo "print each param from \"\$*\"" for var in "$*" do echo "$var" done echo "print each param from \"\$@\"" for var in "$@" do echo "$var" done [root@RockyLinux ~]# bash different.sh qin huai is a boy print each param from "$*" qin huai is a boy print each param from "$@" qin huai is a boy
特殊状态变量 1 2 3 4 $ ? 上一次命令执行状态返回值,0正确,非0失败 $ $ 当前shell脚本的进程号 $ ! 上一次后台进程的PID $ _ 在此之前执行的命令的最后一个参数
脚本控制返回值 脚本返回值的玩法们学习shell函数编程之后,才能彻底理解。脚本返回值就是这个脚本执行完毕之后,会返回一个数字id,这个数字id就是返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@RockyLinux ~]# cat t1.sh # !/bin/bash [ $# -ne 2 ] && { echo "错误,你必须输入两个参数" exit 110 } echo "正确,输入的是两个参数" [root@RockyLinux ~]# bash t1.sh qin huai nb 错误,你必须输入两个参数 [root@RockyLinux ~]# echo $? 110 [root@RockyLinux ~]# bash t1.sh qin huai 正确,输入的是两个参数 [root@RockyLinux ~]# echo $? 0
获取上次后台执行的程序的pid 1 2 3 4 5 6 7 8 9 [root@RockyLinux ~]# nohup ping www.baidu.com & 1> /dev/null [1] 459865 [root@RockyLinux ~]# nohup: ignoring input and appending output to 'nohup.out' [root@RockyLinux ~]# echo $! 459865 [root@RockyLinux ~]# ps -ef | grep ping root 459865 394171 0 14:26 pts/0 00:00:00 ping www.baidu.com root 462854 394171 0 14:27 pts/0 00:00:00 grep --color=auto ping
获取当前脚本的pid 1 2 3 4 5 6 7 8 9 10 11 [root@RockyLinux ~]# cat t1.sh # !/bin/bash [ $# -ne 2 ] && { echo "错误,你必须输入两个参数" exit 110 } echo "正确,输入的是两个参数" echo '当前脚本的pid是:' $$ [root@RockyLinux ~]# bash t1.sh qin huai 正确,输入的是两个参数 当前脚本的pid是: 470511
获取上次命令的最后一个参数 1 2 3 4 5 [root@RockyLinux ~]# bash t1.sh qin huai 正确,输入的是两个参数 当前脚本的id是: 486392 [root@RockyLinux ~]# echo $_ huai
shell子串 bash的基础内置命令 1 2 3 4 5 6 echo eval exec export read shift
echo命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 -n 不换行输出 -e 解析字符串中的特殊符号 \n 换行 \r 回车 \t 制表符,有四个空格 \b 退格 [root@RockyLinux ~]# echo -n 我是旺仔小乔;echo -n 你们好吗? 我是旺仔小乔你们好吗?[root@RockyLinux ~]# [root@RockyLinux ~]# echo -e "我是旺仔小乔\n你们好吗?" 我是旺仔小乔 你们好吗? [root@RockyLinux ~]# echo -e "我是旺仔小乔\t你们好吗?" 我是旺仔小乔 你们好吗?
eval命令 执行多个命令
1 2 3 [root@RockyLinux /]# eval ls;cd /tmp afs bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var [root@RockyLinux tmp]#
exec命令 不创建子进程执行后续命令,且执行完毕后自动exit,如果没有切换到其他用户则直接退出当前会话。
1 2 3 4 5 6 7 8 9 10 11 12 exec ping[root@RockyLinux ~]# exec ping -c 4 www.baidu.com PING www.a.shifen.com (110.242.69.21) 56(84) bytes of data. 64 bytes from 110.242.69.21 (110.242.69.21): icmp_seq=1 ttl=53 time=35.8 ms 64 bytes from 110.242.69.21 (110.242.69.21): icmp_seq=2 ttl=53 time=35.6 ms 64 bytes from 110.242.69.21 (110.242.69.21): icmp_seq=3 ttl=53 time=35.2 ms 64 bytes from 110.242.69.21 (110.242.69.21): icmp_seq=4 ttl=53 time=34.9 ms --- www.a.shifen.com ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3005ms rtt min/avg/max/mdev = 34.853/35.364/35.794/0.367 ms 连接断开
shell变量子串 1 2 3 4 5 6 7 8 9 10 11 $ {变量} 返回变量值 $ { $ {变量:start} 返回变量start数值之后的字符 [root@RockyLinux ~]# echo ${name:0:7} qinhuai $ {变量 $ {变量 $ {变量%word} 从变量结尾删除最短的word $ {变量%%word} 从变量结尾开始删除最长匹配的word $ {变量/pattern/string} 用string代替第一个匹配的pattern $ {变量//pattern/string} 用string代替所有的pattern
实际案例 shell截取字符串通常有两种方式:从指定位置开始截取和从指定字符(子字符串)开始截取。
从指定位置开始截取:
这种方式需要两个参数:除了指定起始位置,还需要截取长度,才能最终确定要截取的字符串。
既然需要指定起始位置,那么就涉及到计数方向的问题,shell技能从字符串左边开始计数,又能从字符串右边开始计数。
从字符串左边开始计数 如果想从字符串左边开始计数,那么截取字符串的具体格式如下:
${string:start:length}
其中string是要截取的字符串,start是起始位置(从左边开始,从0开始计数),length是要截取的长度(省略的话表示直到字符串的末尾)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 设置变量 [root@RockyLinux ~]# name="qinhuai666" [root@RockyLinux ~]# echo $name qinhuai666 统计变量的长度 [root@RockyLinux ~]# echo ${#name} 10 截取字串的用法 1.截取qinhuai [root@RockyLinux ~]# echo ${name:0:7} qinhuai 2.截取后3个字符 [root@RockyLinux ~]# echo ${name:7} 666 3.截取huai [root@RockyLinux ~]# echo ${name:3:4} huai
计算变量长度的各种用法
1 2 3 4 5 6 7 8 9 10 11 12 1.使用wc -L命令统计字符最多的行的长度 [root@RockyLinux ~]# echo $name | wc -L 10 2.利用数值计算expr命令 [root@RockyLinux ~]# expr length "${name}" 10 4.awk统计长度,length函数 [root@RockyLinux ~]# echo ${name} | awk '{print length($0)}' 10 5.最快的统计方式 [root@RockyLinux ~]# echo ${#name} 10
统计命令执行的速度
time命令统计命令执行时长
for循环的shell编程知识
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 time for n in {1..10000};do char=`seq -s "qinhuai" 100`;echo ${#char} &>/dev/null;done 1.使用${#char} [root@RockyLinux ~]# time for n in {1..10000};do char=`seq -s "qinhuai" 100`;echo ${#char} &>/dev/null;done real 0m17.489s user 0m5.325s sys 0m12.260s 2.使用wc -L [root@RockyLinux ~]# time for n in {1..10000};do char=`seq -s "qinhuai" 100`;echo ${char}|wc -L &>/dev/null;done real 0m36.279s user 0m12.872s sys 0m26.328s 3.使用expr [root@RockyLinux ~]# time for n in {1..10000};do char=`seq -s "qinhuai" 100`;expr length ${char} &>/dev/null;done real 0m33.672s user 0m10.839s sys 0m22.934s 4.使用awk的length函数 [root@RockyLinux ~]# time for n in {1..10000};do char=`seq -s "qinhuai" 100`;echo ${char}|awk '{print length($0)}' &>/dev/null;done real 0m48.219s user 0m18.640s sys 0m32.960s
shell编程尽量使用Linux内置的命令,内置的操作和内置的函数,效率最高依托于c语言开发。尽可能的减少管道符的操作。
字符串截取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 从开头删除匹配最短 # % 从结尾删除匹配最短 % %从结尾删除匹配最长 指定字符内容截取,严格区分大小写 a*c 匹配开头为a,中间任意个字符,结尾为c的字符串 $ {变量} 返回变量值 $ { $ {变量:start} 返回变量start数值之后的字符 [root@RockyLinux ~]# echo ${name:0:7} qinhuai $ {变量 $ {变量 $ {变量%word} 从变量结尾删除最短的word $ {变量%%word} 从变量结尾开始删除最长匹配的word $ {变量/pattern/string} 用string代替第一个匹配的pattern $ {变量//pattern/string} 用string代替所有的pattern
删除所匹配到的字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 定义变量 [root@RockyLinux ~]# name="I am qinhuai" [root@RockyLinux ~]# name2="abcABC123ABCabc" [root@RockyLinux ~]# echo -e "${name}\n${name2}" I am qinhuai abcABC123ABCabc 从变量开头匹配删除 [root@RockyLinux ~]# echo ${name2#a*c} ABC123ABCabc [root@RockyLinux ~]# echo ${name2##a*c} 从变量结尾匹配删除 [root@RockyLinux ~]# echo ${name2%a*c} abcABC123ABC [root@RockyLinux ~]# echo ${name2%c*a} #不符合匹配条件就会原样输出 abcABC123ABCabc [root@RockyLinux ~]# echo ${name2%%a*c}
替换字符串
1 2 3 4 5 6 7 8 9 10 [root@RockyLinux ~]# str="Hello,my nickname is qinhuai" [root@RockyLinux ~]# echo $str Hello,my nickname is qinhuai 单个替换 [root@RockyLinux ~]# echo ${str/my/you} Hello,you nickname is qinhuai 多个替换 [root@RockyLinux ~]# echo ${str//i/I} Hello,my nIckname Is qInhuaI
批量修改文件名 实验准备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@RockyLinux test]# touch qinhuai_{1..5}_finished.jpg [root@RockyLinux test]# touch qinhuai_{1..5}_finished.png [root@RockyLinux test]# ll total 0 -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_1_finished.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_1_finished.png -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_2_finished.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_2_finished.png -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_3_finished.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_3_finished.png -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_4_finished.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_4_finished.png -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_5_finished.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_5_finished.png
实验
1.去掉所有文件的_finished字符信息去掉
1 2 3 4 5 6 7 [root@RockyLinux test]# for file_name in `ls *fini*.jpg`;do mv $file_name `echo ${file_name//finished/}`;done [root@RockyLinux test]# ll *.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_1_.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_2_.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_3_.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_4_.jpg -rw-r--r-- 1 root root 0 Sep 18 18:23 qinhuai_5_.jpg
特殊shell扩展变量 变量的处理
1 2 3 4 5 6 7 8 9 10 11 如果parameter变量值为空,返回word字符串 $ {parameter:-word} 如果parameter变量为空,则word替代变量值,且返回其值 $ {parameter:=word} 如果parameter变量值为空,word当作stdrr输出,否则输出变量值。用于设置变量为空导致错误时,返回的错误信息。 $ {parameter:?word} 如果parameter变量为空,什么都不做,否则word返回。 $ {parameter:+word}
实际案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 :- 判断变量如果为空就返回后面的字符信息,可以通过result变量去接收 变量为空的时候 [root@RockyLinux ~]# echo $str1 [root@RockyLinux ~]# result=${str1:-qin} [root@RockyLinux ~]# echo $str1 [root@RockyLinux ~]# echo $result qin 变量不为空的时候 [root@RockyLinux ~]# str2="huai" [root@RockyLinux ~]# echo str2 str2 [root@RockyLinux ~]# result2=${str2:-hello} [root@RockyLinux ~]# echo $result2 huai
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 := 如果变量为空,后面的值会赋值给接收者以及变量本身 变量值为空 [root@RockyLinux ~]# echo str1 str1 [root@RockyLinux ~]# result=${str1:=qinhuai} [root@RockyLinux ~]# echo $str1 $result qinhuai qinhuai 变量值不为空 [root@RockyLinux ~]# str2="你好啊" [root@RockyLinux ~]# echo $str2 你好啊 [root@RockyLinux ~]# result2=${str2:=吃了吗} [root@RockyLinux ~]# echo $result2 $str2 你好啊 你好啊
1 2 3 4 5 6 7 8 :? 当变量值为空的时候,主动抛出的错误信息 [root@RockyLinux ~]# echo ${str1:?} -bash: str1: parameter null or not set [root@RockyLinux ~]# echo ${str1:?该变量值为空} -bash: str1: 该变量值为空 [root@RockyLinux ~]# str1="我是有值的变量" [root@RockyLinux ~]# echo ${str1:?该变量值为空} 我是有值的变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 :+ 当变量为空,什么事都不做否则字符返回给接收者 变量为空 [root@RockyLinux ~]# echo $str1 [root@RockyLinux ~]# result=${str1:+现在变量为空,我会返回值吗?} [root@RockyLinux ~]# echo $result 变量不为空 [root@RockyLinux ~]# str1="变量不为空" [root@RockyLinux ~]# echo $str1 变量不为空 [root@RockyLinux ~]# result=${str1:+现在变量不为空,我就返回值到result了} [root@RockyLinux ~]# echo $result 现在变量不为空,我就返回值到result了
实际应用
数据备份,删除过期数据的脚本
1 2 3 4 5 6 7 find xargs搜索且删除 删除7天以上的过期数据 find 需要搜索的文件路径 -name 搜索的文件名字 -type 文件类型 -mtime +7 | xargs rm -f 如删除数据库备份数据 find ${dir_path:=/data/mysql_back_data/} -name '*.tar.gz' -type f -mtime +7 | xargs rm -f
父子shell
source和点执行脚本,只在当前shell环境中执行生效
指定bash sh解释器运行脚本,是开启subshell,开启子shell运行脚本命令
./script都会指定shebang,通过解释器运行,也是开启subshell运行命令
父shell的概念 ps进程管理命令,查看
1 2 3 4 5 6 7 8 9 ps -ef -f 显示UID,PID,PPID -e 列出所有进程的信息,如图-A选项 ps -ef --forest root 793 1 0 Sep18 ? 00:00:19 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups root 1262594 793 0 11:01 ? 00:00:02 \_ sshd: root [priv] root 1262598 1262594 0 11:01 ? 00:00:22 | \_ sshd: root@pts/0,pts/1 #父shell root 1262599 1262598 0 11:01 pts/0 00:00:00 | \_ -bash #子shell1 root 1418574 1262599 0 11:52 pts/0 00:00:00 | | \_ ps -ef --forest #子shell2
子shell的概念
多个子shell
创建进程列表 需要执行一系列的shell命令。
shell的列表进程理念需要使用到(),如下执行方式就称之为进程列表。
1 (cd ~;ls;cd /tmp/;pwd;ls)
检测是否在子shell环境中 BASH_SUBSHELL是Linux默认的有关shell的变量。该变量的值的特点是如果为0就是在当前shell环境中执行的,否则就是开辟子shell去运行的。
检测是否开启了子shell运行命令
1 2 3 4 5 6 7 [root@RockyLinux ~]# cd ~;pwd;ls;cd /tmp/;pwd;ls;echo $BASH_SUBSHELL /root anaconda-ks.cfg frp test /tmp systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-chronyd.service-bTH9z4 systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-irqbalance.service-NOHu0g systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-dbus-broker.service-Xw0rPy systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-systemd-logind.service-EHB2nG 0
明确开启子shell运行的命令,进程列表并且开启子shell命令。
1 2 3 4 5 6 7 [root@RockyLinux ~]# (cd ~;pwd;ls;cd /tmp/;pwd;ls;echo $BASH_SUBSHELL) /root anaconda-ks.cfg frp test /tmp systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-chronyd.service-bTH9z4 systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-irqbalance.service-NOHu0g systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-dbus-broker.service-Xw0rPy systemd-private-0125e1b4a92744f19f63164dc0eb9ffa-systemd-logind.service-EHB2nG 1
子shell嵌套运行 嵌套多个小括号运行命令可以开启多个子shell。利用括号()开启子shell,以及检查在shell脚本开发中会经常使用子shell进行多进程的处理,提高程序并发执行效率。
1 2 3 4 [root@RockyLinux ~]# (pwd;(pwd;(echo $BASH_SUBSHELL))) /root /root 3
shell内置命令、外置命令 1 2 内置命令:在系统启动时就载入内存,常驻于内存之中,执行效率更高,但是占用资源。 外置命令:系统需要从硬盘中读取程序文件,在读入内存加载。
外置命令也就是自己单独下载安装的文件系统命令,处于bash shell之外的程序,常存放的地址如下。
1 2 3 4 /bin /usr/bin /sbin /usr/sbin
通过Linux的type 命令可以分辨命令是否是内置、外置命令
内置命令不会产生子进程去执行,内置命令和shell是为一体的,是shell的一部分,不需要单独去读取某个文件,系统启动后就执行在内存中了。
外置命令的特点是一定会开启子进程实行。
1 2 3 使用compgen -b查看Linux的内置shell命令 [root@RockyLinux ~]# compgen -b | xargs . : [ alias bg bind break builtin caller cd command compgen complete compopt continue declare dirs disown echo enable eval exec exit export false fc fg getopts hash help history jobs kill let local logout mapfile popd printf pushd pwd read readarray readonly return set shift shopt source suspend test times trap true type typeset ulimit umask unalias unset wait
shell数学运算 shell中常见的算数运算符号
shell中常见的算数运算命令
shell的一些基础命令,只支持整数的运算,小数的运算需要用到如bc这样的命令。
双小括号(())
数值计算脚本开发 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@RockyLinux test]# cat shuzhijisuan.sh # !/bin/bash print_err(){ printf "请按要求输入正确的字符!!!\n" exit 1 } read -p "请输入第一个需要计算的数字:" first_number if [ -n "`echo ${first_number} | sed 's/[0-9]//g'`" ] then print_err fi read -p "请输入正确的运算符(+ - * /):" operator if [ "${operator}" != "+" ] && [ "${operator}" != "-" ] && [ "${operator}" != "*" ] && [ "${operator}" != "/" ] then print_err fi read -p "请输入第二个需要计算的数字:" second_number if [ -n "`echo ${second_number} | sed 's/[0-9]//g'`" ] then print_err fi echo "${first_number}${operator}${second_number}的结果是:$((${first_number}${operator}${second_number}))"
let命令 let命令的执行效果等同于双小括号,但是双括号效率更高。
1 2 3 4 [root@RockyLinux test]# num1=2 [root@RockyLinux test]# let num1=num1+10 [root@RockyLinux test]# echo $num1 12
检测nginx存活的脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [root@RockyLinux test]# cat check_nginx_status.sh # !/bin/bash CheckNginx(){ read -p "请输入你要检测的网站:" WebUrl timeout=10 failed=0 successed=0 #循环检测 echo -e "---------------------------------------------------------------------\n正在检测网站的状态\n---------------------------------------------------------------------" while [ -n $WebUrl ] do wget --timeout=${timeout} --tries=1 ${WebUrl} -q -O /dev/null if [ $? -ne 0 ] then let failed+=1 else let successed+=1 fi #当successed大于等于1的时候就可以判断网站存活,可以正常访问 if [ ${successed} -ge 1 ] then echo "该网站处于健康状态!" exit 0 fi #当failedd的值大于等于2的时候就告警 if [ ${failed} -ge 2 ] then echo "该网站处于异常状态!!!!!!" exit 119 fi done } CheckNginx
expr命令 简单的计算器执行命令。expr命令也并不好用,基于空格传入参数,但是在shell里一些元字符都是有特殊含义的。
1 2 3 4 5 6 [root@RockyLinux test]# expr 5 + 3 8 [root@RockyLinux test]# expr 5 * 3 expr: syntax error: unexpected argument ‘check_nginx_status.sh’ [root@RockyLinux test]# expr 5 \* 3 15
expr还可用于求参数的长度expr length 字符串
1 2 3 4 5 6 [root@RockyLinux test]# expr length 1234356765() -bash: syntax error near unexpected token `(' [root@RockyLinux test]# expr length 1234356765*() 13 [root@RockyLinux test]# expr length 1234356765*(()) 15
expr还可用于逻辑判断,0为错,1为正确
1 2 3 4 [root@RockyLinux test]# expr 5 \< 6 1 [root@RockyLinux test]# expr 5 \> 6 0
expr模式匹配 expr也支持模式匹配功能,其中有两个特殊符号。
: 冒号,计算字符串的字符数量,如qinhuai 7个字符
.* 任意的字符串重复0次或者多次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 expr 字符串 ":" ".*" 统计字符个数 [root@RockyLinux test]# expr qinhuai ":" ".*" 7 匹配模式可自定义且输出匹配到的时候的字符,后边字符不再理会 [root@RockyLinux test]# expr hello.jpg ":" ".*hello" 5 [root@RockyLinux test]# expr hello.jpg ":" ".*\.jpg" 9 [root@RockyLinux test]# expr hello.jpeg ":" ".*\.jpg" 0 [root@RockyLinux test]# expr hello.jpggggggggggg ":" ".*\.jpg" 9
expr命令判断文件名后缀的合法性 执行脚本,传入一个文件名,然后判断该文件是否为合法文件
expr命令的模式匹配功能,字符串匹配上了就统计其长度,匹配不上就返回0,在shell中,0就是为假的意思,非0就是真。
对真假条件判断的不同条件执行使用if-else语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@RockyLinux test]# cat filename_check.sh # !/bin/bash if expr "$1" ":" ".*\.jpg" &> /dev/null then echo "文件名命名合法!!" else echo "文件名命名不合法!!" fi [root@RockyLinux test]# bash filename_check.sh qh.jpg 文件名命名合法!! [root@RockyLinux test]# bash filename_check.sh qh.jpd 文件名命名不合法!! [root@RockyLinux test]# bash filename_check.sh qh.jpgg 文件名命名合法!!
可以看到上方的脚本测试,以jpgg结尾的也可以识别为正常的文件,所以需要对文件名的长度进行判断才能严格判断文件名的合法性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@RockyLinux test]# cat filename_check.sh # !/bin/bash if [ `expr "$1" ":" ".*\.jpg"` -eq `expr length "$1"` ] then echo "文件名命名合法!!" else echo "文件名命名不合法!!" fi [root@RockyLinux test]# bash filename_check.sh qh.jpg 文件名命名合法!! [root@RockyLinux test]# bash filename_check.sh qh.jpgg 文件名命名不合法!! [root@RockyLinux test]# bash filename_check.sh qh.jpggjpg 文件名命名不合法!!
bc命令 bc命令当作计算器来用的,命令行的计算器。
交互式的操作 进入中断内进行加减乘除的运算,并且支持小数的运算。
1 2 3 4 5 6 7 [root@RockyLinux test]# bc bc 1.07.1 Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc. This is free software with ABSOLUTELY NO WARRANTY. For details type `warranty'. 2.3*2 4.6
bc结合管道符 1 2 3 4 5 6 7 8 9 10 11 12 [root@RockyLinux test]# echo "2.3*5" | bc 11.5 [root@RockyLinux test]# result=`echo "2.56*0.37" | bc` [root@RockyLinux test]# echo $result .94 [root@RockyLinux test]# num1="2.4" [root@RockyLinux test]# num2="3.1" [root@RockyLinux test]# result=`echo "$num1*$num2" | bc` [root@RockyLinux test]# echo $result 7.4
bc案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 1. [root@RockyLinux test]# echo {1..100} 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 [root@RockyLinux test]# echo {1..100} | tr " " "+" 1+2+3+4+5+6+7+8+9+10+11+12+13+14+15+16+17+18+19+20+21+22+23+24+25+26+27+28+29+30+31+32+33+34+35+36+37+38+39+40+41+42+43+44+45+46+47+48+49+50+51+52+53+54+55+56+57+58+59+60+61+62+63+64+65+66+67+68+69+70+71+72+73+74+75+76+77+78+79+80+81+82+83+84+85+86+87+88+89+90+91+92+93+94+95+96+97+98+99+100 [root@RockyLinux test]# echo {1..100} | tr " " "+" |bc 5050 2. [root@RockyLinux test]# seq -s "+" 100 1+2+3+4+5+6+7+8+9+10+11+12+13+14+15+16+17+18+19+20+21+22+23+24+25+26+27+28+29+30+31+32+33+34+35+36+37+38+39+40+41+42+43+44+45+46+47+48+49+50+51+52+53+54+55+56+57+58+59+60+61+62+63+64+65+66+67+68+69+70+71+72+73+74+75+76+77+78+79+80+81+82+83+84+85+86+87+88+89+90+91+92+93+94+95+96+97+98+99+100 [root@RockyLinux test]# seq -s "+" 100 | bc 5050 3. [root@RockyLinux test]# echo $((`seq -s "+" 100` )) 5050 4.expr命令计算稍微有点复杂,expr命令是接受多个参数来计算的,expr接受以空格分割的多个参数,需要配合xargs来进行计算 [root@RockyLinux test]# seq -s " + " 100 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 + 100 [root@RockyLinux test]# seq -s " + " 100 | xargs 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 + 100 [root@RockyLinux test]# seq -s " + " 100 | xargs expr 5050
awk计算 awk也支持小数计算。
1 2 3 4 5 6 [root@RockyLinux test]# echo "2.4 3.5" | awk '{print $1+$2}' 5.9 [root@RockyLinux test]# echo "2.4 3.5" | awk '{print $1*$2}' 8.4 [root@RockyLinux test]# echo "2.4 3.5" | awk '{print ($1*2+$2)}' 8.3
中括号计算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ [表达式] [root@RockyLinux test]# num1=22 [root@RockyLinux test]# result=$[num1*2] [root@RockyLinux test]# echo $result 44 [root@RockyLinux test]# result=$[result-20] [root@RockyLinux test]# echo $result 24 [root@RockyLinux test]# result=$[result+num1] [root@RockyLinux test]# echo $result 46
shell条件测试 读取用户输入 shell变量除了直接赋值,或者脚本传参,还有就是read命令读取,read也是内置命令。
1 2 3 -p 设置提示信息 -t 等待用户输入超时,timeout read -p "提示信息" 变量名
条件测试
通过条件测试得出真假,shell提供条件测试的语法常为test命令和[ ]中括号。
test条件测试 test命令评估一个表达式他的结果是真还是假,如果条件为真,那么命令执行状态码结果就为0,否则就是不为0,通过$?取值。
参数
解释
关于某个文件名的类型侦测存在与否,如test -e filename
-e
该文件名(普通文件或目录)是否存在,常用
-f
该文件名是否为文件(file),常用
-d
该文件名是否为目录(directory),常用
-b
该文件是否为一个block device装置
-c
该文件是否为一个character device装置
-S
该文件是否为一个Socket文件
-p
该文件名是否为一个FIFO(Pipe 管道)文件
-L
该文件名是否为一个连接档
关于该文件的权限侦测,如test -r filename
-r
侦测该文件是否具有可读的属性
-w
侦测该文件是否具有可写的属性
-x
侦测该文件是否具有可执行的属性
-u
侦测该文件是否具有SUID的属性
-g
侦测该文件是否具有SGID的属性
-k
侦测该文件是否具有Sticky bit的属性
-s
侦测该文件是否为空白文件
两个文件之间的比较,如:test file1 -nt file2
-nt
(newer than)判断file1是否比file2新
-ot
(older than)判断file2是否比file2旧
-ef
判断file1与file2是否为同一文件,可用在hard link(硬链接)的判定上,主要意义在判定两个文件是否均指向同一个inode
关于两个整数之间的判定,例如test n1 -eq n2
-eq
两个数值相等(equal)
-ne
两个数值不相等(not equal)
-gt
n1 大于 n2(greater than)
-lt
n1 小于 n2(less than)
-ge
n1 大于等于 n2(greater than or equal)
-le
n1 小于等于 n2 (less than or equal)
判定字符串的数据
-z
判定字符串是否为0,若字符串为空则为true
-n
判定字符串是否为0,若字符串为空则返回false
=
判定str1是否等于str2,若相等则返回true
!=
判定str1是否不等于str2,若相等则回传false
多重条件判定,例如test -r filename -a -x filename
-a
and,两个状况同时成立,例如test -r file -a -x file,当file文件同时具有读和执行权限才回传true
-o
or,两个状况任何一个成立了,例如test -r file -o -x file,file文件具有读或者执行权限时就回传true
!
反状态,如test ! -x file,当file不具备x时,回传true
1 2 3 4 5 6 7 8 简单演示 [root@RockyLinux test]# test -e check_nginx_status.sh [root@RockyLinux test]# echo $? 0 [root@RockyLinux test]# test -e check_nginx_status.py [root@RockyLinux test]# echo $? 1
test命令实践 shell对于真假判断的逻辑,提供&&与运算,||或运算。
A条件 && B条件,当A条件成立,并且执行B条件。
A条件 || B条件,当A条件不成立的时候才会执行B条件。
1 2 判断文件是否存在,若不存在则创建 test -e filename && echo "该文件已存在,不执行创建操作" || touch filename
中括号条件测试 脚本中经常进行条件测试,用的最多的都是中括号[ ],test和[ ]的作用都是一样的。
需要注意的是中括号里前后的空格都必须要有,另外在条件测试中使用变量必须要添加双引号!!!
1 2 3 4 5 6 7 8 9 [root@RockyLinux test]# filename="qinhuai.png" [root@RockyLinux test]# touch ${filename} [root@RockyLinux test]# [ -e "${filename}" ] && echo "文件已存在,无需创建" || touch "${filename}" 文件已存在,无需创建 [root@RockyLinux test]# rm -f ${filename} [root@RockyLinux test]# [ -e "${filename}" ] && echo "文件已存在,无需创建" || touch "${filename}" [root@RockyLinux test]# ls qinhuai.png
双中括号条件测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 语法: [[ 条件判断 ]] [qinhuai@RockyLinux ~]$ ll total 0 -r--r--r-- 1 qinhuai qinhuai 0 Sep 20 19:40 test [qinhuai@RockyLinux ~]$ [[ -w "test" ]] && echo "你有写入的权限,可以对文件进行写入" >> test || echo "你没有写入的权限,禁止向文件中写入数据!" 你没有写入的权限,禁止向文件中写入数据! [qinhuai@RockyLinux ~]$ chmod u+w test [qinhuai@RockyLinux ~]$ [[ -w "test" ]] && echo "你有写入的权限,可以对文件进行写入" >> test || echo "你没有写入的权限,禁止向文件中写入数据!" [qinhuai@RockyLinux ~]$ [qinhuai@RockyLinux ~]$ [[ -r "test" ]] && cat test || echo "你没有文件读取的权限,禁止你读取文件!" 你有写入的权限,可以对文件进行写入 [qinhuai@RockyLinux ~]$ chmod u-r test [qinhuai@RockyLinux ~]$ ll total 4 --w-r--r-- 1 qinhuai qinhuai 52 Sep 20 19:46 test [qinhuai@RockyLinux ~]$ [[ -r "test" ]] && cat test || echo "你没有文件读取的权限,禁止你读取文件!" 你没有文件读取的权限,禁止你读取文件!
字符串比较测试
数值比较测试
逻辑判断
测试表达式符号的选择
if语句 单分支if语句 1 2 3 4 5 6 7 8 9 if <条件表达式> then 执行的代码 fi 简化: if <条件表达式>;then 执行的代码 fi
if-else语句 1 2 3 4 5 6 if <条件表达式> then 条件成立的时执行的代码 else 条件不成立时执行的代码 fi
嵌套if语句 1 2 3 4 5 6 7 8 if <条件表达式> then 执行的代码 if <条件表达式> then 执行的代码 fi fi
if-elif语句 if-elif的嵌套不能超过三层!!!
1 2 3 4 5 6 7 8 9 10 11 12 if <条件表达式> then 执行的代码1 elif <条件表达式> then 执行的代码2 elif <条件表达式> then 执行的代码3 else 执行的代码4 fi
系统监控脚本 思路:
1.获取当前内存的情况
2.配置邮件告警,使用Linux发送邮件,邮件的内容是内存剩余情况
3.开发脚本,判断剩余内存是否小于100M,if判断
4.脚本加入定时任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@RockyLinux script]# cat memory_check.sh # !/bin/bash # 获取当前内存的情况,即使用free -m获取available的值,它就是现实系统可以提供给应用程序可用的内存大小 MemAvailable=$(free -m | awk 'NR==2{print $NF}') # 邮件提示信息 MailNotice="当前可用内存为:$MemAvailable MB" EorrNotice="内存已不足1G,请及时查看服务器内存情况并维护!!!" # 判断内存是否小于阈值 if [ $MemAvailable -lt "3500" ];then echo -e "`date +%F" "%T`${MailNotice}\n${EorrNotice}" > /tmp/messages.txt mail -s "`date +%F" "%T`$MailNotice" 1826049145@qq.com < /tmp/messages.txt fi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 现在所使用的操作系统是rocky Linux,安装mail服务命令发生了改变,以下是各个系统安装mail的命令 Red Hat系 # 如果使用CentOS,其软件包普遍比较老旧,如果没有s-nail,就安装名为mailx软件包: yum install mailx # 如果使用Fedora或者CentOS Stream,使用下面的命令: dnf install s-nail 安装的版本是:s-nail-14.9.23-1.el8.x86_64 Debian系 apt install s-nail Debian系的s-nail软件包可能不提供mail和mailx命令,而是使用s-nail命令。可以通过下面的命令创建mail命令。 ln -s s-nail /usr/bin/mail Arch Linux系 pacman -S s-nail 安装完mail后还会出现配置问题,对于s-nail v15的版本配置略有变化。 cat ~/.mailrc set smtp-auth=login set smtp-use-starttls set from=xxxx@qq.com set v15-compat set mta='smtp://xxxx%40qq.com:password@smtp.domain:587'
如果你想用此脚本对服务器进行内存监测的话可以使用定时任务。
1 2 3 [root@RockyLinux script]# crontab -e [root@RockyLinux script]# crontab -l */3 * * * * /bin/bash /root/test/script/memory_check.sh &> /dev/null
rsync的启停脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 [root@RockyLinux script]# cat rsync_up_down.sh # !/bin/bash # 对传入的参数进行验证判断,一个参数则开始脚本运行,多个参数则进行报错 if [ "$#" -ne 1 ];then echo "Usage:$0 {start|stop|restart}" exit 1 fi # 用户选择是否启停服务 if [ "$1" = "start" ];then /usr/bin/rsync --daemon sleep 5 if [ `netstat -tunlp | grep rsync | wc -l` -ge 1 ];then echo "rsync is started!!!" exit 0 else echo "rsync start up error!!!" exit 11 fi elif [ "$1" = "stop" ];then pkill rsync &> /dev/null sleep 5 if [ `netstat -tunlp | grep rsync | wc -l` -lt 1 ];then echo "rsync is stoped!!!" exit 0 elif echo "rsync shadown error" exit 21 fi elif [ "$1" = "restart" ];then pkill rsync &> /dev/null sleep 5 stoped=`netstat -tunlp | grep rsync | wc -l` /usr/bin/rsync --daemon sleep 5 started=`netstat -tunlp | grep rsync | wc -l` if [ "$stoped" -lt 1 -a "$started" -ge 1 ];then echo "rsync restarted successfully!!!" exit 0 else echo "Error restarting rsync!!!" exit 31 fi else echo "Usage:$0 {start|stop|restart}" exit 1 fi [root@RockyLinux script]# bash rsync_up_down.sh ddd Usage:rsync_up_down.sh {start|stop|restart} [root@RockyLinux script]# bash rsync_up_down.sh stop rsync is stoped!!! [root@RockyLinux script]# bash rsync_up_down.sh start rsync is started!!! [root@RockyLinux script]# netstat -tunlp | grep rsync tcp 0 0 0.0.0.0:873 0.0.0.0:* LISTEN 1243555/rsync tcp6 0 0 :::873 :::* LISTEN 1243555/rsync [root@RockyLinux script]# bash rsync_up_down.sh stop rsync is stoped!!! [root@RockyLinux script]# bash rsync_up_down.sh restart rsync restarted successfully!!! [root@RockyLinux script]# netstat -tunlp | grep rsync tcp 0 0 0.0.0.0:873 0.0.0.0:* LISTEN 1256456/rsync tcp6 0 0 :::873
case语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 语法 case $变量名 in "值1"|"类值1") 如果变量值为1,则执行这条语句 ;; "值2") 如果变量值为2,则执行这条语句 ;; "值3") 如果变量值为3,则执行这条语句 ;; *) 如果变量值都不是以上的条件值,则执行这条语句 ;; esac
注意:
case行尾必须为单词in,每一个模式匹配必须以右括号)结束。
双分号;;表示命令序列结束,相当于C语言中的break。
最后的“)表示默认模式,相当于C语言中的default。
值如果是正则表达式可以用下面这些字符:
1 2 3 4 5 * 任意字串 ? 任意字元 [abc] a, b, 或c三字元其中之一 [a-n] 从a到n的任一字元 | 多重选择
for循环 1 2 3 4 5 6 7 8 9 10 11 12 语法 1. for..in for 变量名 in 字符串组 do 执行的命令 done 2. for((赋值;条件;运算语句)) for ((赋值;条件;运算语句)) do 执行的命令 done
while循环 1 2 3 4 5 语法 while [ 条件测试 ] do 执行的命令 done
until循环 1 2 3 4 until [ 条件测试 ] do 执行的命令 done
shell函数开发 函数的特点,类似于alias别名一样,能够简化Linux命令的操作,让整个命令更易读更易用。
函数,就是将你需要执行的shell命令组合起来组合成一个函数体。
还得给整个函数体起一个名字,这个名字就称之为函数名。
函数名字+函数体。
如果后面想执行这个函数就使用这个函数名字即可。
使用函数的好处
先定义函数
再使用函数
将相同的程序定义封装为一个函数,能够减少程序的代码数量,提高开发效率,使用函数能够写更少的代码并且函数能够增加程序的可读性,易读性。
shell函数语法
1 2 3 4 5 6 function() { 函数体 } 调用函数 function
shell函数开发写法 shell函数定义的语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 标准shell函数定义 function 函数名() { 函数体 要执行的Linux命令 return 返回值 } 简化写法,当函数名前加了function可以省略括号 function 函数名{ 函数体 要执行的Linux命令 return 返回值 } 超级简易写法,但必须带有括号 函数名() { 函数体 要执行的命令 return 返回值 }
执行函数的基础概念 有关函数执行的基础概念:
执行shell函数,直接写函数名字即可无需添加其他内容。
函数必须先定义,再执行。shell脚本自上而下加载。
函数体内定义的变量称之为局部变量。
函数体内需要添加return语句,作用是退出函数,且赋予返回值给调用该函数的程序,也就是shell脚本。再shell脚本中,定义使用函数,shell脚本执行结束后,通过$?获取其return的返回值。
函数如果单独写入一个文件,需要用source读取。
函数内使用local关键字定义局部变量。
return语句和exit不同之处:
return是结束函数的执行,返回一个退出值、返回值。
exit是结束shell环境,返回一个退出值、返回值给当前的shell。
函数实践 在同一个shell文件中定义和使用函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@RockyLinux fuctions]# cat func_test.sh # !/bin/bash # 定义函数 function test1(){ cd /tmp echo "我将会在/tmp目录下创建一个文件并写入信息" echo "这是我通过定义函数调用后写入的信息" >> ./func_test.txt return 0 } test1 [root@RockyLinux fuctions]# bash func_test.sh 我将会在/tmp目录下创建一个文件并写入信息 [root@RockyLinux fuctions]# cat /tmp/func_test.txt 这是我通过定义函数调用后写入的信息
在不同的shell文件中定义和使用函数 函数定义和执行分开在不同的文件之中,Linux自带的诸多脚本都是基于该形式使用的。
函数写在一个文件中只定义不执行。
另一个脚本读取该函数文件,且加载该函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 1.生成一个定义函数的文件 [root@RockyLinux fuctions]# cat functions.sh # !/bin/bash # 定义的函数 func_test1 (){ echo "这是一个只定义在文件中的函数,不会执行,用于其他文件调用执行该函数" return 0 } 2.检查当前的shell环境变量 [root@RockyLinux fuctions]# set | grep ^func 3.利用"."或者source命令读取shell脚本,能够加载其变量到当前的shell环境中 [root@RockyLinux fuctions]# source functions.sh 4.再次检查环境变量,就会有从脚本中加载的变量了 [root@RockyLinux fuctions]# set | grep ^func func_test1 () 5.退出当前shell环境重新进入后加载的函数变量就会消失,此时需要重新加载脚本中的函数。 6.创建另一个脚本文件,从该文件对函数func_test1 ()进行调用 [root@RockyLinux fuctions]# cat func_test3.sh # !/bin/bash # 对文件进行条件测试是否存在,存在即调用函数,不存在就退出 if [ -f /root/test/script/fuctions/functions.sh ];then . /root/test/script/fuctions/functions.sh func_test1 exit 0 else echo "该文件不存在,请检查!!!" exit 1 fi 7.执行func_test3.sh文件 [root@RockyLinux fuctions]# bash func_test3.sh 这是一个只定义在文件中的函数,不会执行,用于其他文件调用执行该函数 8.将functions.sh文件移除再执行脚本查看 [root@RockyLinux fuctions]# mv functions.sh functions.sh.bak [root@RockyLinux fuctions]# bash func_test3.sh 该文件不存在,请检查!!!
函数脚本传参 在functions.sh中定义新的函数,此函数用于接收参数。
1 2 3 4 5 6 7 8 [root@RockyLinux fuctions]# cat functions.sh # !/bin/bash # 脚本传参函数示例 parameter(){ echo "传入脚本的参数依次是:$1、$2、$3,一共$#个参数" return 0 }
创建func_test4.sh文件,调用新创建的传参函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@RockyLinux fuctions]# cat func_test4.sh # !/bin/bash # 对文件进行条件测试是否存在,存在即调用函数,不存在就退出 if [ -f /root/test/script/fuctions/functions.sh ];then . /root/test/script/fuctions/functions.sh parameter $1 $2 $3 exit 0 else echo "该文件不存在,请检查!!!" exit 1 fi
执行func_test4.sh文件并传入参数,函数只会接收三个参数,多余的不会再接收。
1 2 3 4 [root@RockyLinux fuctions]# bash func_test4.sh qin huai blog 传入脚本的参数依次是:qin、huai、blog,一共3个参数 [root@RockyLinux fuctions]# bash func_test4.sh qin huai blog nb 传入脚本的参数依次是:qin、huai、blog,一共3个参数
网站存活检测函数版 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@RockyLinux fuctions]# cat functions.sh # !/bin/bash # 网站存活检测的函数 usage(){ echo "$0 url" exit 1 } UrlCheck(){ wget --spider --tries=1 -T 5 -q -o /dev/null $1 # 对状态码进行判断网站是否正常 if [ "$?" -eq 0 ];then echo "$1 is working" else echo "$1 is down" fi } WebCheck(){ # 判断用户输入是否正确 if [ "$#" -ne 1 ];then usage fi # 用户输入正确调用网站检测函数 UrlCheck $1 }
新建一个脚本文件,对网站存活函数进行调用
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@RockyLinux fuctions]# cat webcheck.sh # !/bin/bash # 对文件进行条件测试是否存在,存在即调用函数,不存在就退出 if [ -f /root/test/script/fuctions/functions.sh ];then . /root/test/script/fuctions/functions.sh WebCheck $* exit 0 else echo "该文件不存在,请检查!!!" exit 1 fi
脚本执行
1 2 3 4 5 6 [root@RockyLinux fuctions]# bash webcheck.sh blog.7464824.top blog.7464824.top is working [root@RockyLinux fuctions]# bash webcheck.sh www.7464824.top www.7464824.top is down [root@RockyLinux fuctions]# bash webcheck.sh dadas adad webcheck.sh url


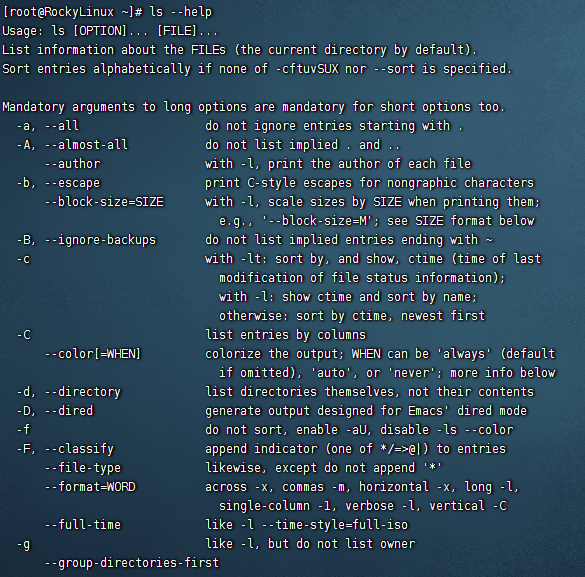

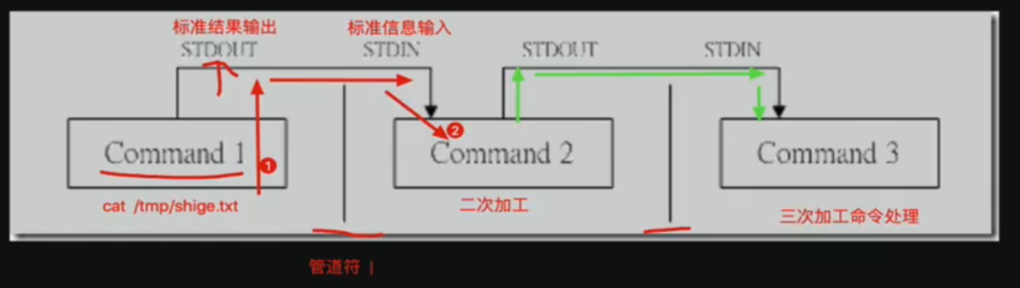


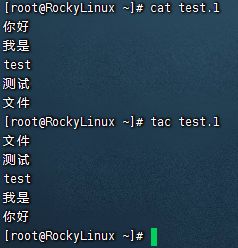
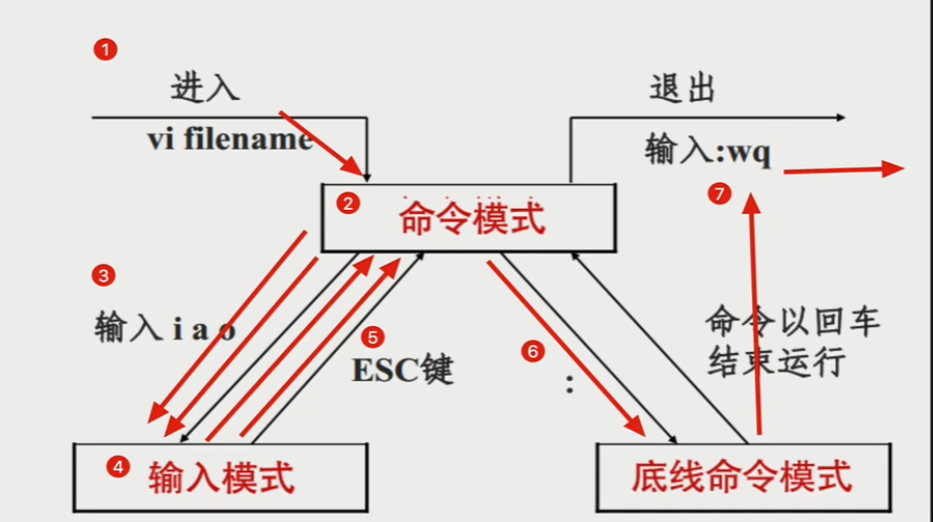
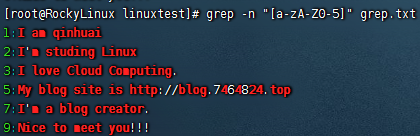
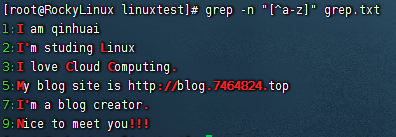
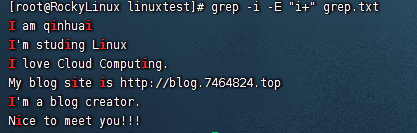
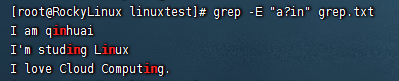

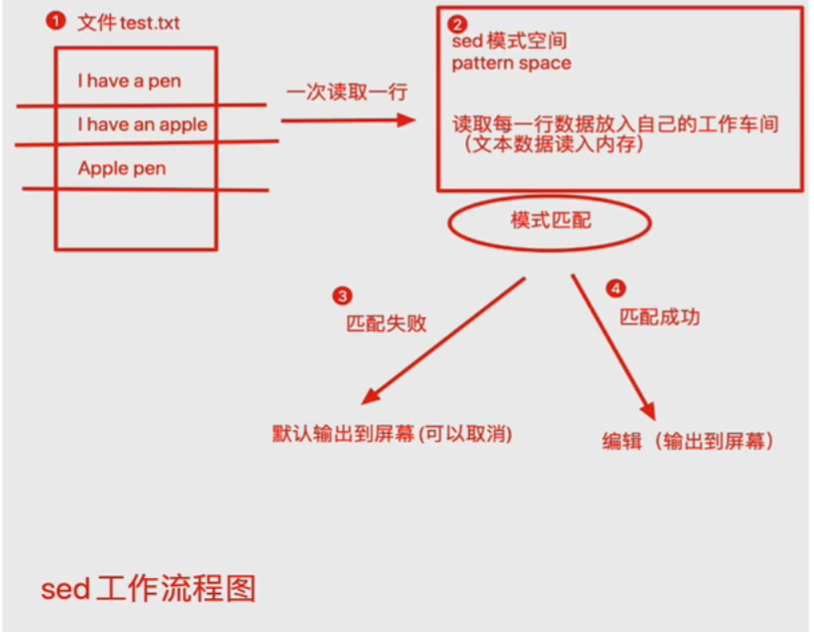
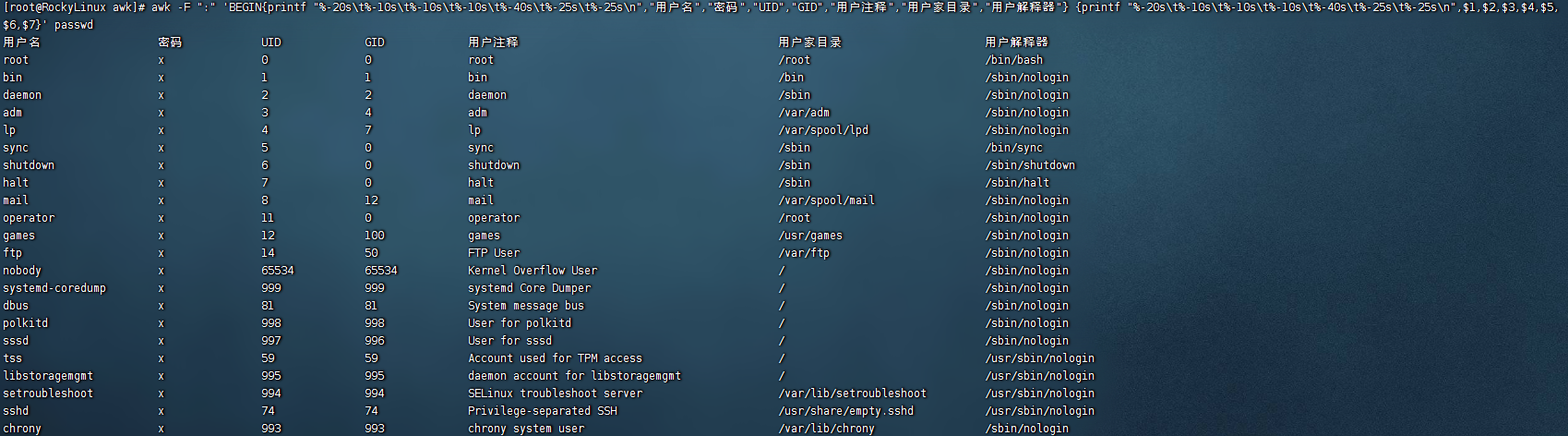
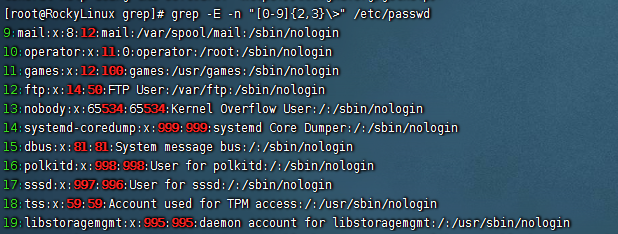


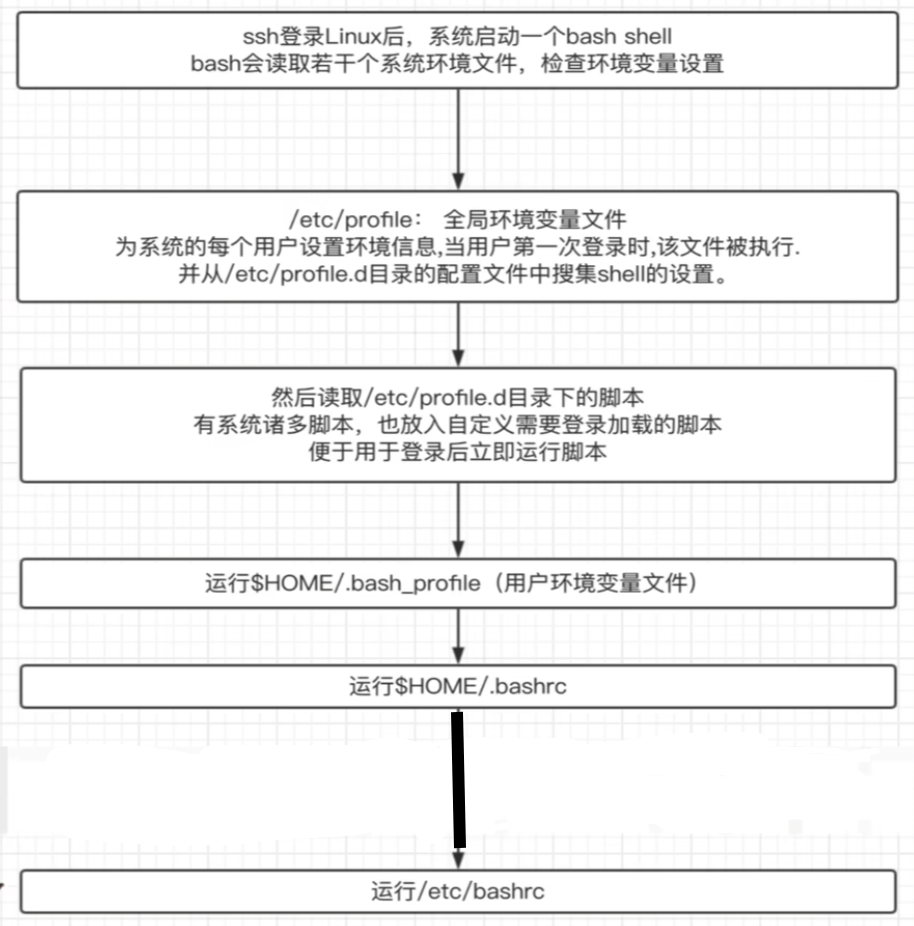
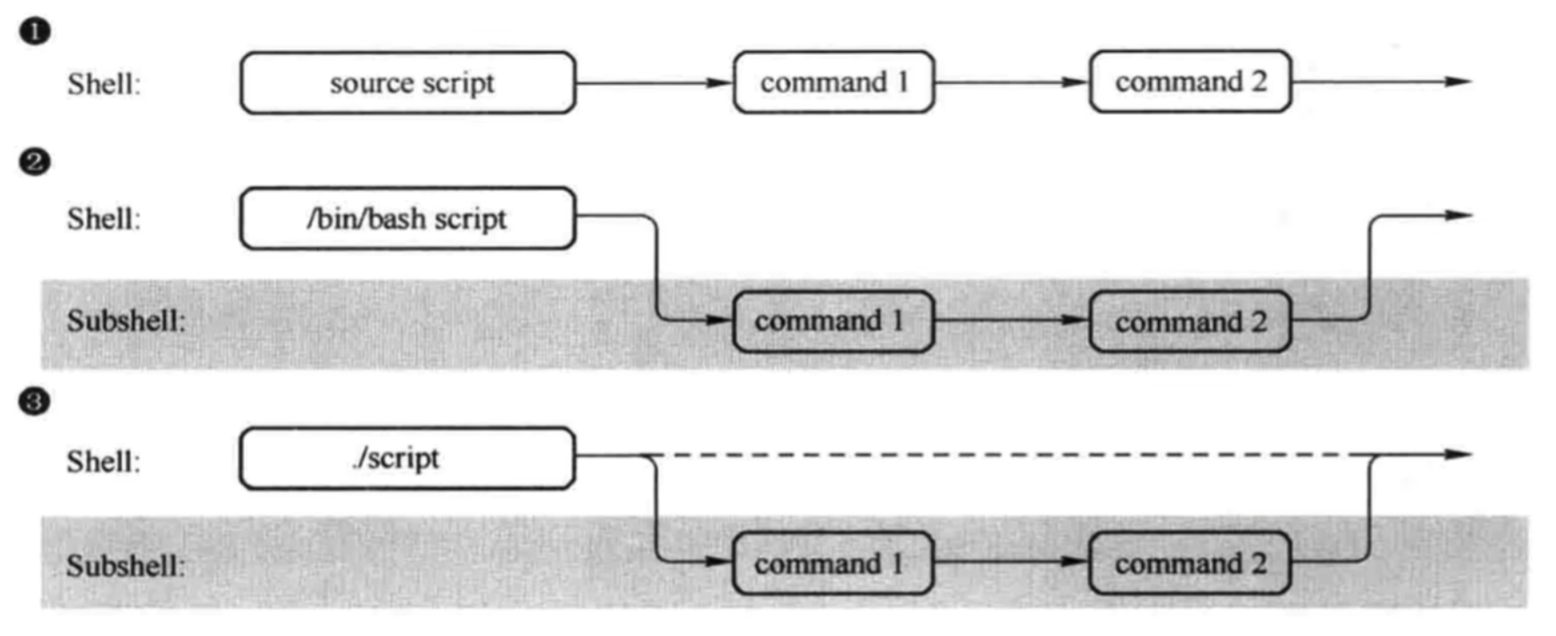
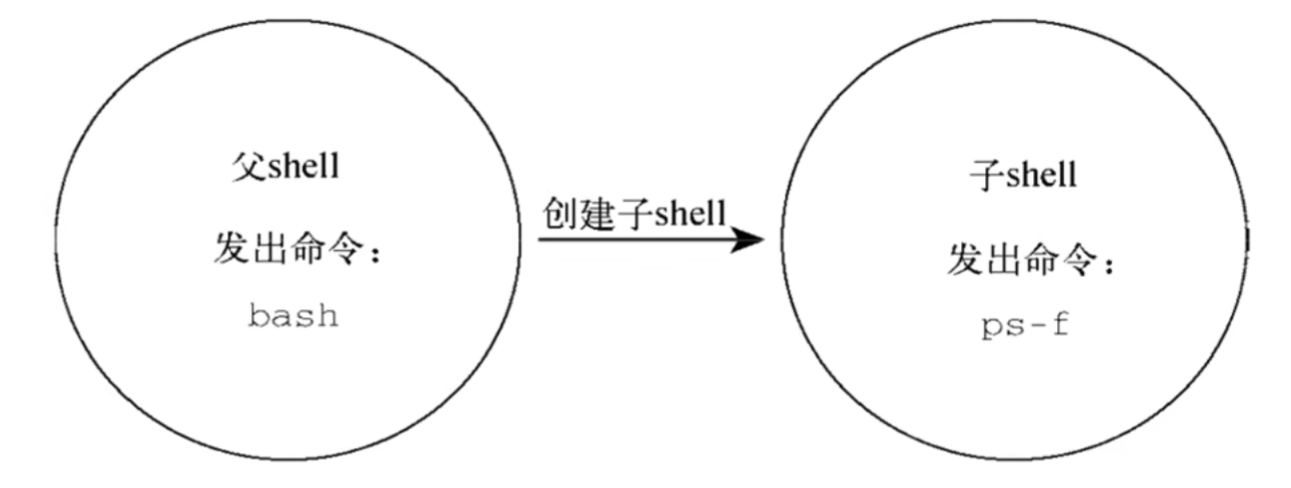
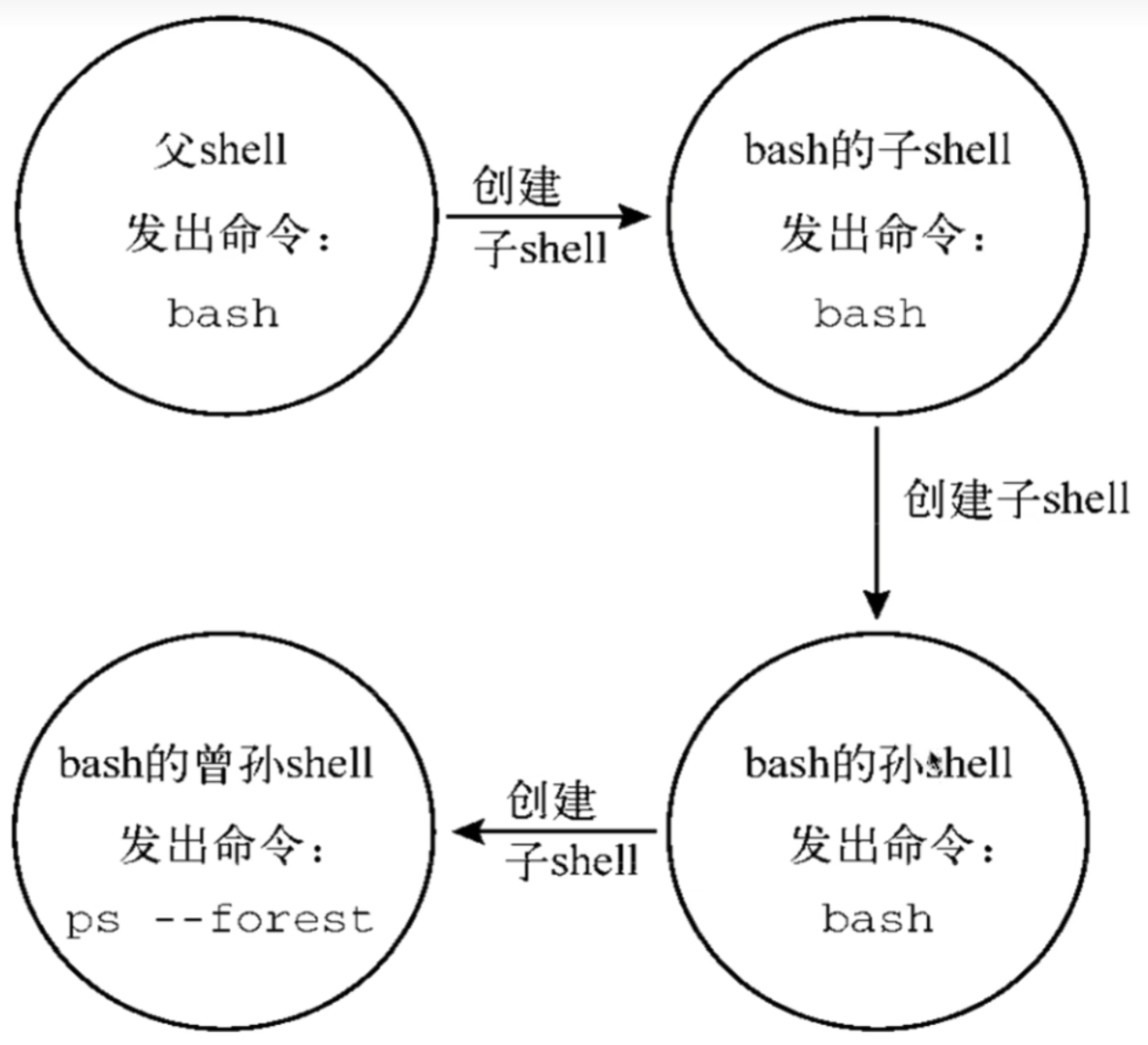

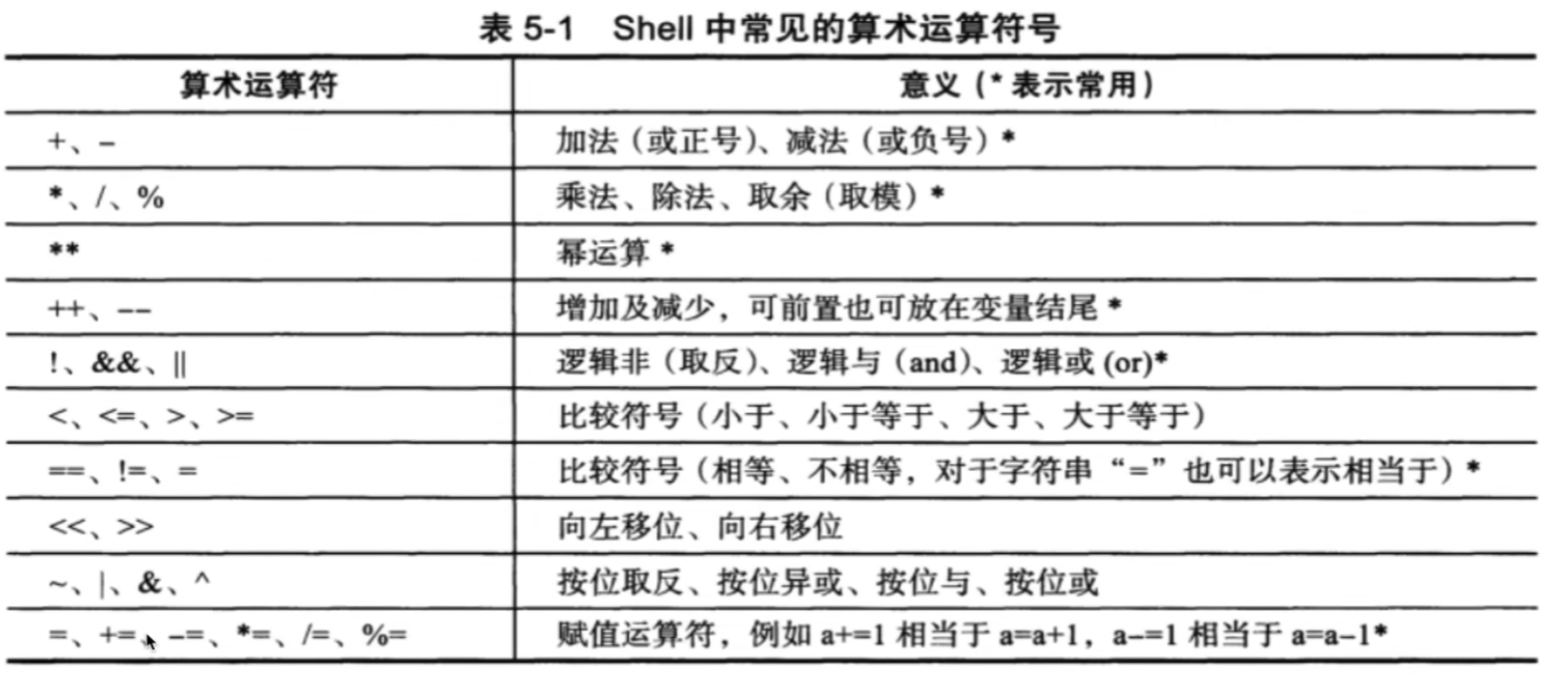




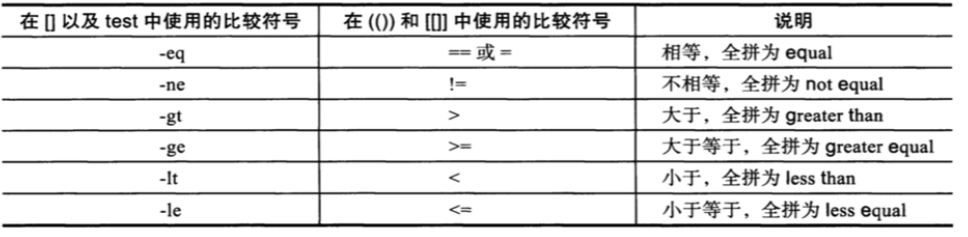

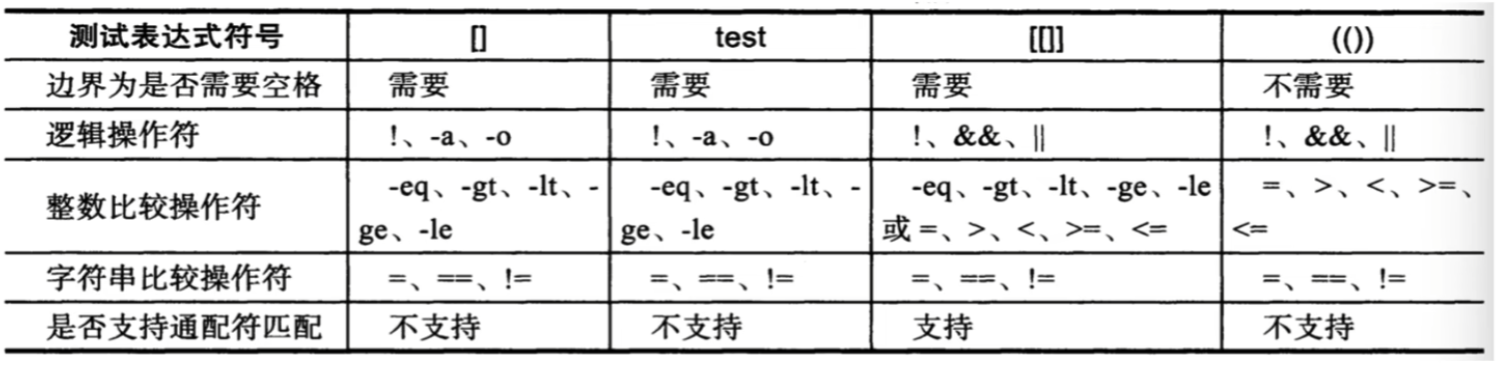
 微信
微信 支付宝
支付宝